已弃用!! 最新版本已迁移至:Introduce · Awesome (ariescat.top)
《技术总结》
思想是灵魂,实现是形式
Java基础
String
-
正则表达式
-
- 数组呢?
-
StringJoiner(Java 8中提供的可变字符串类)
-
char
JAVA的char内部编码为
UTF-16,而与Charset.defaultCharset()无关 -
String s = new String(“a”) 到底产生几个对象?
对于通过new产生一个字符串(”a”)时,会先去常量池中查找是否已经有了”a”对象,如果没有则在常量池中创建一个此字符串对象,然后堆中再创建一个常量池中此”a”对象的拷贝对象。
也就是说准确答案是产生了一个或两个对象,如果常量池中原来没有”a”,就是两个。反之就是一个。
是的!如果面试官问到,回答一个或两个即可,但是…毕竟…毕竟
毕竟我和在座的各位都是人才,Java知识底蕴不能如此短浅,这题还没谢幕我们还能对面试官多哔哔几句:字符串常量池在不同版本的jvm中可能位置不同,那么这又是一个老梗了。(在JDK6.0及之前版本,字符串常量池是放在Perm Gen区(也就是方法区)中;在JDK7.0版本,字符串常量池被移到了堆中了)
扩展:
-
intern方法
-
关键点是 jdk7 中常量池不在 Perm 区域了,这块做了调整。常量池中不需要再存储一份对象了,可以直接存储堆中的引用
-
-
此外,Java中的常量池有字符串常量池、class常量池和运行时常量池。原文
-
常量池会被回收吗?
-
基本类型
-
强转
long转int注意:最高位为1强转会为负数!如:正数2147483648(long类型)强转int会变成负数,
(int)0x80000000 => -2147483648(Integer.MIN_VALUE) -
无符号类型
- java中无符号类型的解决方案
- Java8包装类 新增 无符号运算方法
- byte转换int时与0xff进行与运算的原因
枚举
-
RegularEnumSet里面有这样一行代码:elements = -1L >>> -universe.length;无符号右移一个负数!是一个负移位量!
换个例子看一下:
-1 >>> -5其实等同-1 >>> 27;-1L >>> -5等同-1L >>> 59如果移位量超过位数:
-1 >>> 32其实等同-1 >>> 0;-1 >>> 33等同-1 >>> 1
数组
-
二维数组按行和按列遍历效率?
- CPU高速缓存
- 内存分页调度
日期与时间
Date和Calendar,LocalDateTime(Java8),ZonedDateTime(时区),Instant
LocalDate/LocalTime 类:
Java 8新增了LocalDate和LocalTime接口,为什么要搞一套全新的处理日期和时间的API?因为旧的java.util.Date实在是太难用了。
java.util.Date月份从0开始,一月是0,十二月是11,变态吧!java.time.LocalDate月份和星期都改成了enum,就不可能再用错了。
java.util.Date和SimpleDateFormatter都不是线程安全的,而LocalDate和LocalTime和最基本的String一样,是不变类型,不但线程安全,而且不能修改。
Instant:
Instant获取的是UTC的时间,而Date是根据当前服务器所处的环境的默认时区来获取的当前时间。
泛型
擦拭,extends通配符,super通配符
问题:
为什么泛型编译期擦除了,getGenericSuperclass或反射等还能获取得到?
Java泛型类型擦除与运行时类型获取 - linghu_java - 博客园 (cnblogs.com)
位运算
-
^“异或运算”的特殊作用:(1)使特定位翻转找一个数,对应X要翻转的各位,该数的对应位为1,其余位为零,此数与X对应位异或即可。
例:X=10101110,使X低4位翻转,用X ^ 0000 1111 = 1010 0001即可得到。
(2)与0相异或,保留原值 ,X ^ 0000 0000 = 1010 1110。
-
~取反:注意最高位也会取反
集合
Java集合比如说HashMap和ConcurrentHashMap我觉得,最好在平时能去耐心读一下源码,搜一搜相关的博客,最好能知道每个参数为什么设置成这么大?有什么好处?为什么?
-
HashMap
最近它有两个主要的更新——一个在Java 7u40版本中对于空map的共享的底层存储,以及在Java 8中将底层hash bucket链接成为哈希树(改进更差情况下的性能)。
- jdk1.7中的线程安全问题 (resize死循环)
- jdk8中是如何解决jdk7中的HashMap死循环的
- IdentityHashMap:和HashMap最大的不同,就是使用==而不是equals比较key
-
jdk8 ConcurrentHashMap
-
死循环:
-
死锁(该问题由fly提出并收录):
ConcurrentHashMap<Integer, Integer> map = new ConcurrentHashMap<>(); map.put(1, 1); map.put(2, 2); Thread t1 = new Thread(() -> { LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(2)); map.computeIfAbsent(4, key -> { map.clear(); System.out.println("4"); return key; }); }); Thread t2 = new Thread(() -> { LockSupport.parkNanos(TimeUnit.SECONDS.toNanos(2)); map.computeIfAbsent(3, key -> { map.clear(); System.out.println("3"); return key; }); }); t1.start(); t2.start(); t1.join(); t2.join(); System.out.println("finish");ConcurrentHashMap 1194行会死锁

-
-
红黑树 TreeMap、TreeSet
-
Queue 接口的几个方法
add/offer, remove/poll, element/peek
-
其他
-
WeakHashMap
-
CopyOnWriteArrayList (附:Redis写快照的时候,用到了Linux底层的Copy-On-Write技术)
-
DelayQueue
ScheduledThreadPoolExecutor其任务队列默认是DelayedWorkQueue的变种
-
-
著名BUG
-
c.toArray might (incorrectly) not return Object[] (see 6260652) 原文
java.util.ArrayList元素类型为Object[] elementData,toArray()方法实质返回Object[]java.util.Arrays.ArrayList元素类型为E[] a,toArray()方法实质返回E[]因此,虽然
List的toArray接口表面都返回Object[],但他们的实质返回值还是有差的。所以我们不能将其他类型的对象,放进java.util.Arrays.ArrayList#toArray()返回的数组中。List<String> list = Arrays.asList("abc"); // class java.util.Arrays$ArrayList System.out.println(list.getClass()); Object[] objArray = list.toArray(); // class [Ljava.lang.String; System.out.println(objArray.getClass()); // cause ArrayStoreException objArray[0] = new Object();
-
-
第三方原始类型集合库Koloboke,避免大量的装箱拆箱,同类型的还有HPPC,Eclipse Collections等
Koloboke的目标是替换标准的Java集合和流的API,提供更高效的实现。
异常
- Error和Exception的区别
IO
-
IO流
-
对文件进行操作:FileInputStream(字节输入流),FileOutputStream(字节输出流),FileReader(字符输入流),FileWriter(字符输出流)
2020年3月17日追加:
FileReader,可以理解成他把FileInputStream和Decoder封装了起来,本质上还是用FileInputStream读了一层字节流byte[] (这里的read是一个native方法),然后通过Decoder把他转成了char[]。BufferedReader,他默认开辟了一份defaultCharBufferSize = 8192长度的cb[]数组(缓冲区),读之前会把这个数组fill()满,之后都是操作这个数组,操作完了就再次更新数组,提高数据访问的效率。
测试代码:
study-metis: com.ariescat.metis.base.io.iostream.Test -
对管道进行操作:PipedInputStream(字节输入流),PipedOutStream(字节输出流),PipedReader(字符输入流),PipedWriter(字符输出流)
PipedInputStream的一个实例要和PipedOutputStream的一个实例共同使用,共同完成管道的读取写入操作,主要用于线程操作。
有空看看这里的实现 简介,源码分析和示例
在一个线程里使用PipedInputStream和PipedOutputStream会造成死锁:这意味着,如果你用同一个线程既读又写(read()和write()方法是阻塞的方法),那么就会造成这个线程的死锁。
-
字节/字符数组:ByteArrayInputStream,ByteArrayOutputStream,CharArrayReader,CharArrayWriter
在内存中开辟了一个字节或字符数组。
-
Buffered缓冲流:BufferedInputStream,BufferedOutputStream,BufferedReader,BufferedWriter
带缓冲区的处理流,缓冲区的作用的主要目的是:避免每次和硬盘打交道,提高数据访问的效率。
-
转化流:
InputStreamReader:在读入数据的时候将字节转换成字符。
OutputStreamWriter:在写出数据的时候将字符转换成字节。
-
数据流:DataInputStream,DataOutputStream
因为平时若是我们输出一个8个字节的long类型或4个字节的float类型,那怎么办呢?可以一个字节一个字节输出,也可以把转换成字符串输出,但是这样转换费时间,若是直接输出该多好啊,因此这个数据流就解决了我们输出数据类型的困难。数据流可以直接输出float类型或long类型,提高了数据读写的效率。
-
打印流:printStream,printWriter
一般是打印到控制台,可以进行控制打印的地方和格式,其中的 print方法不会抛出异常,可以通过checkError方法来查看异常。
-
对象流:ObjectInputStream,ObjectOutputStream
把封装的对象直接输出,而不是一个个在转换成字符串再输出。
-
RandomAccessFile随机访问文件java.io包中是一个特殊的类, 既可以读文件,也可以写文件。
有空也要看看这里的实现,log4j2的Appender里就有这个:
RandomAccessFileAppender、RollingRandomAccessFileAppenderRandomAccessFile的绝大多数功能,但不是全部,已经被JDK 1.4的nio的内存映射文件(memory-mapped files)给取代了,你该考虑一下是不是用”内存映射文件”来代替RandomAccessFile了。
-
ZipInputStream、ZipOutputStream
读取zip文档 getNextEntry、putNextEntry 得到或创建ZipEntry对象。
-
-
Path/Files
-
JDK NIO
- Channel,Buffer,Selector
- 高性能IO之Reactor模式
-
为什么要用
close()关掉流?有些资源
GC回收不掉?
Java Util包
-
BitSet
JDK中的BitSet集合对是布隆过滤器中经常使用的数据结构Bitmap的相对简单的实现。BitSet采用了Bitmap的算法思想。
-
ServiceLoader
Java中SPI全称为(Service Provider Interface,服务提供者接口)
该类通过在资源目录META-INF/services中放置提供者配置文件来标识服务提供者。
应用场景:
-
JDBC驱动加载
java.sql.DriverManager#loadInitialDrivers这里调用了ServiceLoader.load(Driver.class);因此只要pom引入了
mysql-connector-java这个包,就会加载jar包下META-INF/services/java.sql.Driver文件中的com.mysql.jdbc.Driver类,而com.mysql.jdbc.Driver在静态代码块里往DriverManager注册了自己的驱动。所以以后就不用写下面的a段代码啦。//a.导入驱动,加载具体的驱动类 Class.forName("com.mysql.jdbc.Driver"); //b.与数据库建立连接 connection = DriverManager.getConnection(URL, USERNAME, PASSWORD); -
netty/Java的NIO采用SelectorProvider创建:
io.netty.channel.nio.NioEventLoop#provider而
java.nio.channels.spi.SelectorProvider#provider采用了SPI -
Dubbo的扩展点加载
Dubbo的SPI扩展是自己实现的,在启动加载的时候会依次从以下目录中读取配置文件:
META-INF/dubbo/internal/、META-INF/dubbo/、META-INF/services/
——《高可用可伸缩微服务架构:基于Dubbo、Spring Cloud和Service Mesh》3.2.3节 Dubbo Extension机制
-
-
Observable
操作Vector型变量obs的四个方法都加有同步关键字,Vector类型为线程安全的,而上述四个方法为什么还要加同步关键字呢?
-
Arrays
-
几个类:
TimSort,ComparableTimSort,DualPivotQuicksort
-
几个方法:
binarySort 折半插入排序
mergeSort
-
Java lang包
-
Math
-
log
在java中求log2N,首先要弄明白一个初中学到的公式
log2N=logeN/loge2,logeN代表以e为底的N的对数,loge2代表以e为底的2的对数在java.lang.math类中的log(double a)代表以e为底的a的对数,因此log2N在Java中的表示为
log((double)N)/log((double)2) -
pow
-
Javax
-
Java 注解处理器 (Annotation Processor)
javax.annotation.processing.AbstractProcessor 编译时执行
Swing/Awt
-
EventQueue 与 AWTEvent
from https://github.com/jzyong/game-server.git
game-tool/src/main/java/com/jzy/game/tool/db/DBTool.java
java.awt.EventQueue.invokeLaterEventQueue里有一条dispatchThread线程,在postEventPrivate里检测为null则进行初始化,然后一直调用pumpEvents取出优先级最高的AWTEvent进行分发:eq.dispatchEvent(event);如
java.awt.Component#dispatchEventImpl里会触发各种监听 -
Polygon,区域超区校验
Java多线程
概述
JUC包,毫无疑问的,得去学,哪怕平时编程根本不去用,但是得会,至少得知道有这个东西,至少得知道aba,cas,aqs,unsafe,volatile,sync,常见的各种lock,死锁,线程池参数和如何合理的去设置,必须明白自旋,阻塞,死锁和它如何去定位,oom如何定位问题,cpu过高如何定位等基本的操作。你可以没有生产调试经验,但不代表你可以不会top,jps,jstack,jmap这些可能会问的东西。
线程创建
链接:Java并发的四种风味
线程状态
-
java.lang.Thread.State,里面的注释内容讲解得很清楚了链接:
中断线程
?何时抛出 {@see java.lang.InterruptedException}
守护线程
守护线程是指为其他线程服务的线程。在JVM中,所有非守护线程都执行完毕后,无论有没有守护线程,虚拟机都会自动退出。
因此,JVM退出时,不必关心守护线程是否已结束。
线程同步与安全
-
几个问题
-
Bounded-Buffer问题:
生产者消费者问题(Producer-consumer problem),也称有限缓冲问题(Bounded-buffer problem),是一个多线程同步问题的经典案例。原文
-
并发中的伪共享问题(false sharing):
CPU缓存是以缓存行(cache line)为单位存储的。缓存行通常是 64 字节,并且它有效地引用主内存中的一块地址。并发的修改在一个缓存行中的多个独立变量,看起来是并发执行的,但实际在CPU处理的时候,是串行执行的,并发的性能大打折扣。
Java中通过填充缓存行,sun.misc.Contended注解来解决伪共享问题。LMAX Disruptor
Sequence采用了填充缓存行。并不是所有的场景都需要解决伪共享问题,因为CPU缓存是有限的,填充会牺牲掉一部分缓存。
-
锁:
synchronized
-
Java对象头
在JVM中,对象在内存中的布局分为三块区域:对象头、实例数据和对齐填充。
- 对象头:Java对象头一般占有2个机器码(在32位虚拟机中,1个机器码等于4字节,也就是32bit,在64位虚拟机中,1个机器码是8个字节,也就是64bit),但是 如果对象是数组类型,则需要3个机器码,因为JVM虚拟机可以通过Java对象的元数据信息确定Java对象的大小,但是无法从数组的元数据来确认数组的大小,所以用一块来记录数组长度。
- 实例数据:存放类的属性数据信息,包括父类的属性信息;
- 对齐填充:由于虚拟机要求 对象起始地址必须是8字节的整数倍。填充数据不是必须存在的,仅仅是为了字节对齐;
-
锁优化
偏向锁、轻量级锁、重量级锁
-
其他锁优化
锁消除、锁粗化
-
Monitor对象
Monitor其实是一种同步工具,也可以说是一种同步机制,它通常被描述为一个对象。
主要特点:
- 对象的所有方法都被“互斥”的执行
- 通常提供singal机制
“ Java对象是天生的Monitor。”
-
总结:
锁 优点 缺点 适用场景 偏向锁 加锁和解锁不需要额外的消耗,和执行非同步方法比仅存在纳秒级的差距。 如果线程间存在锁竞争,会带来额外的锁撤销的消耗。 适用于只有一个线程访问同步块场景。 轻量级锁 竞争的线程不会阻塞,提高了程序的响应速度。 如果始终得不到锁竞争的线程使用自旋会消耗CPU。 追求响应时间。同步块执行速度非常快。 重量级锁 线程竞争不使用自旋,不会消耗CPU。 线程阻塞,响应时间缓慢。 追求吞吐量。同步块执行速度较长。 -
参考:
volatile
Java内存模型中:
volatile变量在写操作之后会插入一个store屏障,在读操作之前会插入一个load屏障。- 一个类的
final字段会在初始化后插入一个store屏障,来确保final字段在构造函数初始化完成并可被使用时可见。
-
几个概念
-
可见性
-
重排序(编译器重排,处理器重排),happen-before原则
-
Java内存模型定义了8种操作来完成主内存和工作内存的变量访问
lock,unlock,read,load,use,assign,stroe,write
-
MESI协议,Store Buffere(存储缓存),Invalidate Queue(失效队列)
搜索关键词(CPU和volatile )
-
内存屏障是什么?如何工作的?如何实现?在哪个层面上实现?
x86架构:
Store Barrier,Store屏障,是x86的”sfence”指令,相当于StoreStore Barriers,强制所有在sfence指令之前的store指令,都在该sfence指令执行之前被执行,发送缓存失效信号,并把store buffer中的数据刷出到CPU的L1 Cache中;所有在sfence指令之后的store指令,都在该sfence指令执行之后被执行。即,禁止对sfence指令前后store指令的重排序跨越sfence指令,使所有Store Barrier之前发生的内存更新都是可见的。
Load Barrier,Load屏障,是x86上的”ifence”指令,相当于LoadLoad Barriers,强制所有在lfence指令之后的load指令,都在该lfence指令执行之后被执行,并且一直等到load buffer被该CPU读完才能执行之后的load指令(发现缓存失效后发起的刷入)。即,禁止对lfence指令前后load指令的重排序跨越lfence指令,配合Store Barrier,使所有Store Barrier之前发生的内存更新,对Load Barrier之后的load操作都是可见的。
Full Barrier,Full屏障,是x86上的”mfence“指令,相当于StoreLoad Barriers,强制所有在mfence指令之前的store/load指令,都在该mfence指令执行之前被执行;所有在mfence指令之后的store/load指令,都在该mfence指令执行之后被执行。即,禁止对mfence指令前后store/load指令的重排序跨越mfence指令,使所有Full Barrier之前发生的操作,对所有Full Barrier之后的操作都是可见的。
参考:
- http://ifeve.com/memory-barriers-or-fences/
- https://www.jianshu.com/p/64240319ed60/ 该博客讲得不错,认真品味每一个字
-
-
特点:
- 通过使用Lock前缀的指令禁止变量在线程工作内存中缓存来保证volatile变量的内存可见性
- 通过插入内存屏障禁止会影响变量内存可见性的指令重排序
- 对任意单个volatile变量的读/写具有原子性,但类似于volatile++这种复合操作不具有原子性
-
参考文章:
-
注意DCL(Double Check Lock,双重检查锁)和被部分初始化的对象
-
非原子操作!!!
-
乐观锁
-
Atomic
-
了解一下LongAdder 与 Striped64
LongAdder 区别于 AtomicLong ,在高并发中有更好的性能体现
ReentrantLock,ReadWriteLock,StampedLock
应用场景的选择
阿里面试官:说一下公平锁和非公平锁的区别?_敖丙-CSDN博客
AQS(AbstractQueuedSynchronizer)
它维护了一个volatile int state(代表共享资源)和一个FIFO线程等待队列(多线程争用资源被阻塞时会进入此队列)。这里volatile是核心关键词
- AQS框架借助于两个类:
- Unsafe(提供CAS操作)
- LockSupport(提供park/unpark操作)
- 与Object类的wait/notify机制相比,park/unpark有两个优点:
- 以thread为操作对象更符合阻塞线程的直观定义
- 操作更精准,可以准确地唤醒某一个线程(notify随机唤醒一个线程,notifyAll唤醒所有等待的线程),增加了灵活性。
- 应用:
- CountDownLatch、CyclicBarrier和Semaphore
- AbstractFuture (一旦调用get就会阻塞)
- JDK Unsafe类(可以了解一下)
- objectFieldOffset
- compareAndSwap…
- 参考链接
- https://blog.51cto.com/14220760/2390586?source=dra
- https://www.jianshu.com/p/da9d051dcc3d
并发容器
-
LinkedBlockingQueue,ConcurrentLinkedQueue等,要看看源码如何实现(offer,take方法)!
-
CopyOnWriteArrayList
-
ConcurrentHashMap (JDK8),ConcurrentHashMapV8 (netty提供)
java8中的ConcurrentHashMap实现已经抛弃了java7中分段锁的设计,而采用更为轻量级的CAS来协调并发,效率更佳。
- computeIfAbsent
-
SkipList(跳表)
-
ConcurrentSkipListMap(使用跳表实现Map)
和使用哈希算法实现Map的另外一个不同之处是:哈希并不会保存元素的顺序,而跳表内所有的元素都是排序的。因此在对跳表进行遍历时,你会得到一个有序的结果。所以,如果你的应用需要有序性,那么跳表就是你不二的选择。
安全点(Safepoint)
GC停顿点,撤销偏向锁(在一个安全点停止拥有锁的线程,具体看流程)
其他
-
ThreadLocal
ThreadLocal有一个value内存泄露的隐患
-
WeakReference 和 ReferenceQueue
这里重点看ReferenceQueue,引用相关请看下面的对象引用小节
-
Callable和Future(since1.5)
在并发编程中,我们经常用到非阻塞的模型,在之前的多线程的三种实现中,不管是继承thread类还是实现runnable接口,都无法保证获取到之前的执行结果。通过实现Callback接口,并用Future可以来接收多线程的执行结果。
Future表示一个可能还没有完成的异步任务的结果,针对这个结果可以添加Callback以便在任务执行成功或失败后作出相应的操作。
- Guava——AbstractFuture
-
ForkJoin
-
CompletableFuture
-
弄懂几个方法:
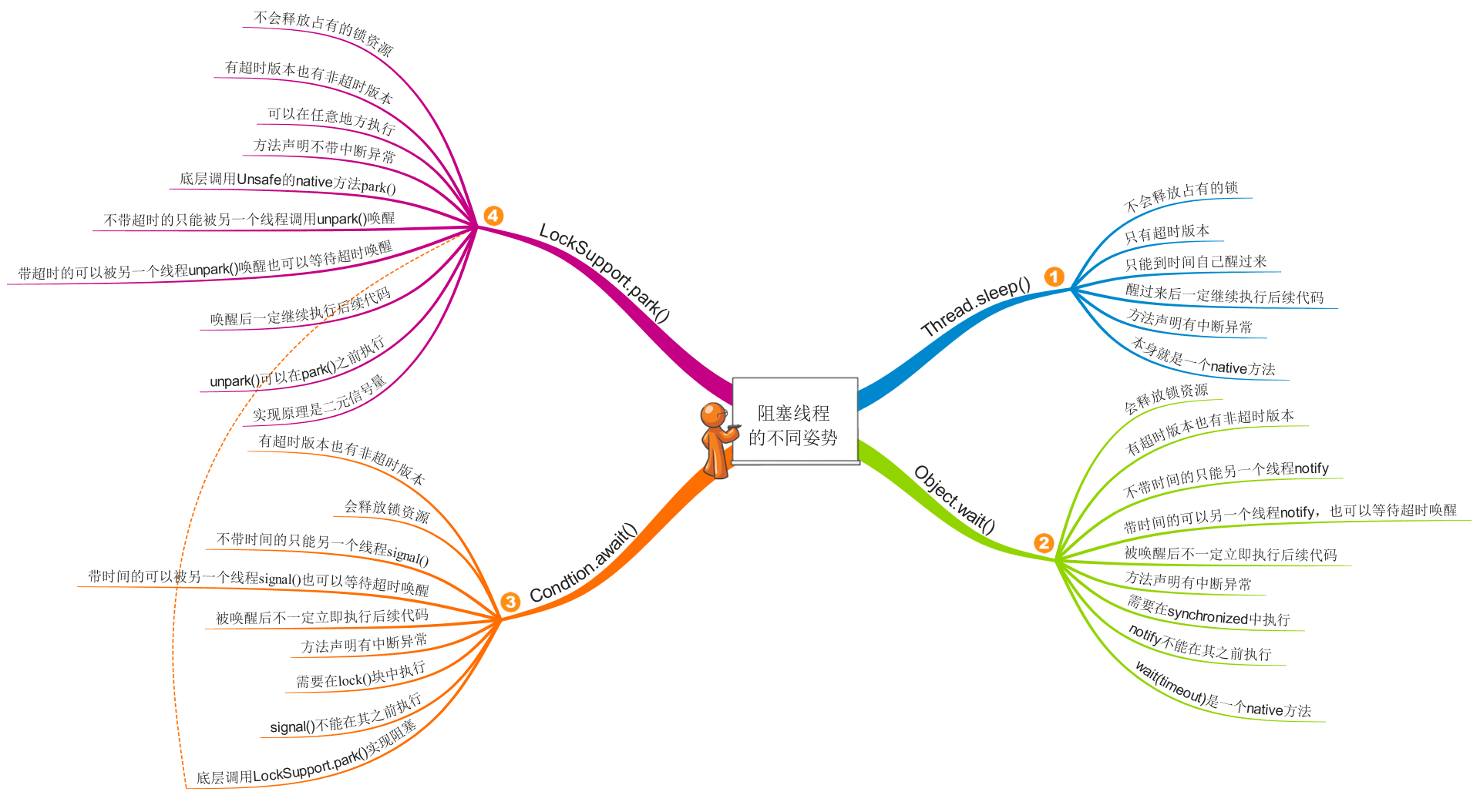
-
synchronized、LockSupport.park(如ReentrantLock)区别
-
wait 和 notify
当使用调用wait时,虽然当前的线程还在schronized同步块中, 但是也会让出锁,要不然,notify永远拿不到锁,永远得不到执行。
同样当使用完notify后,是不会立即释放锁的,必须使你当前线程走完schronized的代码,也就是说只有当前线程走完schronized代码块之后,wait才会被执行。
-
Condition
ReentrantLock和Condition提供的await()、signal()、signalAll() -
Thread.sleep、Object.wait、Condition.await区别,他们会释放锁吗?
-
-
QA?
- 什么是上下文切换?
- 并发与并行的区别?
线程池
介绍:Executor 之 线程池及定时器 (novoland.github.io)
另外:
《阿里巴巴Java开发手册》中强制线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险
Executors 返回线程池对象的弊端如下:
- FixedThreadPool 和 SingleThreadExecutor : 允许请求的队列长度为 Integer.MAX_VALUE ,可能堆积大量的请求,从而导致OOM。
- CachedThreadPool 和 ScheduledThreadPool : 允许创建的线程数量为 Integer.MAX_VALUE ,可能会创建大量线程,从而导致OOM。
三种队列
| 队列 | 简单解释 |
|---|---|
| SynchrousQueue | 不会保存提交任务,超出直接corePoolSize个任务,直接创建新的线程来执行任务,直到(corePoolSize+新建线程) > maximumPoolSize。 |
| LinkedBlockingQueue | 基于链表的先进先出,无界队列。超出直接corePoolSize个任务,则加入到该队列中,直到资源耗尽,所以maximumPoolSize不起作用。 |
| ArrayBlockingQueue | 基于数组的先进先出,创建时必须指定大小,超出直接corePoolSize个任务,则加入到该队列中,只能加该queue设置的大小,其余的任务则创建线程,直到(corePoolSize+新建线程) > maximumPoolSize。 |
上表收录自:线程池的三种缓存队列
解释看起来文邹邹的,要不直接上代码:execute:
int c = ctl.get();
if (workerCountOf(c) < corePoolSize) {
if (addWorker(command, true))
return;
c = ctl.get();
}
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
else if (!addWorker(command, false))
reject(command);
注意几点
-
?
SynchronousQueue误区:很多人把其认为其没有容量,不存储元素,这是错的。好好了解这个结构,并看看其核心算法
transfer。后来实在看不懂…,先记住这句话吧:生产者线程对其的插入操作put必须等待消费者的移除操作take,反过来也一样。你不能调用peek()方法来看队列中是否有数据元素,因为数据元素只有当你试着取走的时候才可能存在,不取走而只想偷窥一下是不行的,当然遍历这个队列的操作也是不允许的。链接:
- https://www.jianshu.com/p/d5e2e3513ba3
- https://www.cnblogs.com/duanxz/p/3252267.html
四种拒绝策略
- AbortPolicy // 默认,队列满了丢任务抛出异常
- DiscardPolicy // 队列满了丢任务不异常
- DiscardOldestPolicy // 将最早进入队列的任务删,之后再尝试加入队列
- CallerRunsPolicy // 如果添加到线程池失败,那么主线程会自己去执行该任务
ThreadPoolExecutor和ScheduledThreadPoolExecutor原理
线程池运行状态
这里有空要详细看看

-
shutdown(),shutdownNow()和awaitTermination()注意,一旦线程池有任务开始跑,就算任务都跑完了,也会等待
keepAliveTime时候后才会停止。一般测试小demo的时候发现程序一直得不到结束,原因基本是这个。public static void main(String[] args) throws InterruptedException { ExecutorService executor = Executors.newCachedThreadPool(); executor.execute(() -> System.err.println("executor")); // TimeUnit.SECONDS.sleep(5L); // executor.shutdown(); System.err.println("finish"); // 两个打印都输出后,程序还要等待 60s 才会结束!! }源码分析:
java.util.concurrent.ThreadPoolExecutor#runWorker这里会一直调用task = getTask(),getTask里会调用workQueue.poll(keepAliveTime, TimeUnit.NANOSECONDS),因此没任务后它也会阻塞keepAliveTime时间。分析一下
shutdown(),它里面调用了interruptIdleWorkers(),它会打断上述的wait keepAliveTime的状态,抛出中断异常,而getTask()会捕获这个异常,从而打破阻塞状态。
协程
协程,英文Coroutines,是一种比线程更加轻量级的存在。正如一个进程可以拥有多个线程一样,一个线程也可以拥有多个协程。最重要的是,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行)。
Java语言并没有对协程的原生支持,但是某些开源框架模拟出了协程的功能,有兴趣的小伙伴可以看一看Kilim框架的源码
Java秃头区
语法糖
有认真了解过Java的语法糖吗?
设计模式
《设计模式之美》值得一看
Class与反射
-
Class
-
关键字 instanceof VS Class.isInstance(参数)
System.err.println(son instanceof Parent); System.err.println(Parent.class.isInstance(son)); -
Class的 getSuperclass与getGenericSuperclass
getGenericSuperclass会包含该超类的泛型。
-
判断当前类是什么类
boolean isLocalClass(); //判断是不是局部类,也就是方法里面的类,其实现:isLocalOrAnonymousClass() && !isAnonymousClass(); boolean isLocalOrAnonymousClass(); boolean isMemberClass(); //判断是不是成员内部类,也就是一个类里面定义的类 boolean isAnonymousClass(); //判断当前类是不是匿名类,一般为实例化的接口或实例化的抽象类 boolean isAnnotation();// 判断Class对象是否是注解类型 boolean isPrimitive(); // 判断Class是否为原始类型(int,double等) boolean isSynthetic(); // 判断是否由Java编译器生成(除了像默认构造函数这一类的)的方法或者类,Method也有这个方法参考:
-
返回字符串(String)的方法
String getCanonicalName() //返回 Java Language Specification 中所定义的底层类的规范化名称。 String getName() //以 String 的形式返回此 Class 对象所表示的实体(类、接口、数组类、基本类型或 void)名称(全限定名:包名.类名)。 String getSimpleName() //返回源代码中给出的底层类的简称。 String toString() //将对象转换为字符串。
-
-
Class.forName和ClassLoader的区别
都可用来对类进行加载。
不同:
1)Class.forName()除了将类的.class文件加载到jvm中之外,还会对类进行解释,执行类中的static块,还会执行给静态变量赋值的静态方法
2)classLoader只干一件事情,就是将.class文件加载到jvm中,不会执行static中的内容,只有在newInstance才会去执行static块。
-
Method.invoke()的实现原理
-
获取Method:
- reflectionData,这个属性主要是SoftReference的
- 我们每次通过调用
getDeclaredMethod方法返回的Method对象其实都是一个新的对象,所以不宜多调哦,如果调用频繁最好缓存起来。不过这个新的方法对象都有个root属性指向reflectionData里缓存的某个方法,同时其methodAccessor也是用的缓存里的那个Method的methodAccessor。
Method调用:
- 其实
Method.invoke方法就是调用methodAccessor的invoke方法
MethodAccessor的实现:
- 所有的方法反射都是先走
NativeMethodAccessorImpl,默认调了15次之后,才生成一个GeneratedMethodAccessorXXX类 - 而
GeneratedMethodAccessorXXX的类加载器会new一个DelegatingClassLoader(var4),之所以搞一个新的类加载器,是为了性能考虑,在某些情况下可以卸载这些生成的类,因为类的卸载是只有在类加载器可以被回收的情况下才会被回收的
并发导致垃圾类创建:
- 假如有1000个线程都进入到创建
GeneratedMethodAccessorXXX的逻辑里,那意味着多创建了999个无用的类,这些类会一直占着内存,直到能回收Perm的GC发生才会回收
其他JVM相关文章:
- 该文章最后有其他JVM相关文章,感觉是干货
-
大量的类加载器
sun/reflect/DelegatingClassLoader,用来加载sun/reflect/GeneratedMethodAccessor类,可能导致潜在的占用大量本机内存空间问题,应用服务器进程占用的内存会显著增大。
-
-
使用Class.getResource和ClassLoader.getResource方法获取文件路径
对于class.getResource(path)方法,其中的参数path有两种形式,一种是以“/”开头的,另一种是不以”/”开头
Class.getClassLoader().getResource(String path),该方法中的参数path不能以“/“开头,path表示的是从classpath下获取资源的
代理
-
按照代理的创建时期,代理类可以分为两种。
静态代理:由程序员创建或特定工具自动生成源代码,再对其编译。在程序运行前,代理类的.class文件就已经存在了。 动态代理:在程序运行时,运用反射机制动态创建而成。
-
Cglib动态代理
JDK的动态代理机制只能代理实现了接口的类,而不能实现接口的类就不能实现JDK的动态代理,cglib是针对类来实现代理的,他的原理是对指定的目标类生成一个子类,并覆盖其中方法实现增强,但因为采用的是继承,所以不能对final修饰的类进行代理。
-
代码实现:Cglib 与 JDK动态代理
-
一些疑惑?
-
为什么cglib为什么生成两个fastclass,
methodProxy.invokeSuper(“代理对象”, args)和methodProxy.invoke(“原对象”, args)虽然底层分别调用两个不同的fastclass,但结果是一样的。// 自定义Cglib代理拦截 public class LQZMethodInterceptor implements MethodInterceptor { /** * @param o cglib生成的代理对象 * @param method 被代理对象方法 * @param objects 方法入参 * @param methodProxy 代理方法 */ public Object intercept(Object o, Method method, Object[] objects, MethodProxy methodProxy) throws Throwable { System.err.println("intercept"); // invokeSuper,o为cglib生成的代理对象 return methodProxy.invokeSuper(o, objects); } }// org.springframework.aop.framework.CglibAopProxy.CglibMethodInvocation#invokeJoinpoint @Override protected Object invokeJoinpoint() throws Throwable { if (this.protectedMethod) { return super.invokeJoinpoint(); } else { // invoke,target为原对象 return this.methodProxy.invoke(this.target, this.arguments); } }可扩展看看
Spring的JdkDynamicAopProxy,其实本质上Spring对代理的处理都差不多
-
创建和销毁对象
单例 与 序列化
一般来说,一个类实现了 Serializable接口,我们就可以把它往内存地写再从内存里读出而”组装”成一个跟原来一模一样的对象。不过当序列化遇到单例时,这里边就有了个问题:从内存读出而组装的对象破坏了单例的规则。单例是要求一个JVM中只有一个类对象的,而现在通过反序列化,一个新的对象克隆了出来。
解决方案:加上readResolve()方法
private Object readResolve() throws ObjectStreamException {
// instead of the object we're on,
// return the class variable INSTANCE
return INSTANCE;
}
对象实例化顺序
1,父类的静态成员变量和静态代码块加载
2,子类的静态成员变量和静态代码块加载
3,父类成员变量和方法块加载
4,父类的构造函数加载
5,子类成员变量和方法块加载
6,子类的构造函数加载
参考:
测试:com.ariescat.metis.base.jdk.TestSameField
java中父类与子类有相同属性调谁?
继承中:
属性:不可被重写,只会被隐藏
方法:会被重写,不会隐藏
多态中,成员变量:
无论编译和运行,都参考左边(引用型变量所属的类)。
也就是说
Fu f = new Zi();
System.out.println(f.age);
打印的还是父类的值。
参考:
对象引用
-
看ThreadLocal源码的时候,其中嵌套类ThreadLocalMap中的Entry继承了WeakReference,为了能搞清楚ThreadLocal,只能先了解下了WeakReference:
WeakReference如字面意思,弱引用, 当一个对象仅仅被 WeakReference(弱引用)指向, 而没有任何其他strong reference(强引用)指向的时候, 如果这时GC运行, 那么这个对象就会被回收,不论当前的内存空间是否足够,这个对象都会被回收。
注意:回收的是WeakReference引用的对象!若存在ReferenceQueue队列,WeakReference本身会入队,但此时get()==null
-
SoftReference 若清楚了上面的原理,SoftReference只是生命周期变成内存将要被耗尽的时候。
下面,我们来总结一下: 1.当发生GC时,虚拟机可能会回收SoftReference对象所指向的软引用,是否被回收取决于该软引用是否是新创建或近期使用过。 2.在虚拟机抛出OutOfMemoryError之前,所有软引用对象都会被回收。 3.只要一个软引用对象由一个强引用指向,那么即使是OutOfMemoryError时,也不会被回收。
那么SoftReference对象到底在GC的时候要不要回收是通过什么公式来判断的呢?
是如下的一个公式:
clock - timestamp <= freespace * SoftRefLRUPolicyMSPerMB
这个公式的意思就是说,“clock - timestamp”代表了一个软引用对象他有多久没被访问过了,freespace代表JVM中的空闲内存空间,SoftRefLRUPolicyMSPerMB代表每一MB空闲内存空间可以允许SoftReference对象存活多久。
-
guava cache:
CacheBuilder.newBuilder().softValues().build()当然 softValues()可以替换成weakKeys() / weakValues() …
实现原理可具体看 com.google.common.cache.LocalCache.Strength
-
LRU缓存实现(Java)
-
原子变量
-
XXXAtomic 原子类
-
AtomicXXXFieldUpdater 原子更新器
在Java5中,JDK就开始提供原子类了,当然也包括原子的更新器——即后缀为FieldUpdater的类
已经有了原子类,为啥还额外提供一套原子更新器呢?
简单的说有两个原因,以int变量为例,基于AtomicIntegerFieldUpdater实现的原子计数器,比单纯的直接用AtomicInteger包装int变量的花销要小,因为前者只需要一个全局的静态变量AtomicIntegerFieldUpdater即可包装volatile修饰的非静态共享变量,然后配合CAS就能实现原子更新,而这样做,使得后续同一个类的每个对象中只需要共享这个静态的原子更新器即可为对象计数器实现原子更新,而原子类是为同一个类的每个对象中都创建了一个计数器 + AtomicInteger对象,这种开销显然就比较大了。
-
对象序列化
ObjectInputStream、ObjectOutputStream
对象拷贝
-
拷贝方式 对象数量: 1 对象数量: 1000 对象数量: 100000 对象数量: 1000000 Hard Code0 ms 1 ms 18 ms 43 ms cglib.BeanCopier111 ms 117 ms 107 ms 110 ms spring.BeanUtils116 ms 137 ms 246 ms 895 ms apache.PropertyUtils167 ms 212 ms 601 ms 7869 ms apache.BeanUtils167 ms 275 ms 1732 ms 12380 ms
热更新
-
自定义类加载器
-
java.lang.instrument
类重新定义,这是Instrumentation提供的基础功能之一,这个类很早就出了,redefineClasses这个方法可以更新方法级别的代码,但是不会触发一个类的初始化方法。
-
第三方工具
-
脚本语言
-
groovy
使用groovy类加载器重载java代码 重载的java文件可以直接使用源文件,无需编译为class
-
JMX
JMX是Java Management Extensions,它是一个Java平台的管理和监控接口。
了解不深==
启动
-
jsvc
在linux上以服务的方式启动java程序,需要提前安装jsvc。linux是利用daemon(jsvc)构建java守护进程。
Java猝死区
JVM
JVM很难,网上错误的观点很多
垃圾回收算法,垃圾收集器,jvm内存模型,每个区域用途,各种oom的种类,jvm调优经验,没有你也要做过,自己去设置启动参数,知道常见参数的含义,类加载过程,双亲委派,什么时候young gc,full gc,各种情况进入老年代的方式,你知道的越多越好,因为吹起来就越自信,举个例子,逃逸分析是什么?markword里面有什么?
内存管理
-
堆是线程共享的内存区域?
不完全正确。因为HotSpot中,TLAB是堆内存的一部分,他在读取上确实是线程共享的,但是在内存分配上,是线程独享的。链接
内存模型,线程,线程安全
- 内存模型
- Monitor对象
- happen-before原则
类加载 ClassLoader
Bootstrap ClassLoader、 Extention ClassLoader、AppClassLoader
Classloader将数据加载到内存中经过的步骤:
- 加载:加载类的二进制数据
- 链接
验证 确保加载的类的正确性。
准备 类中的静态变量分配内存,并且其初始化为默认值。
解析 把类中的符号引用变为直接引用。 - 初始化 为类中的类中的静态变量赋值(正确的初始值)
问题:
-
Q:同一个Class的static字段,被不同的ClassLoader加载,会有产生几份?
A:会是两份,也就是JVM里有两份内存(某次面试时问到的,但自己没试过)
字节码
-
局部变量表中的Slot
为什么JVM局部变量表的一个slot至少要能容纳一个int类型的变量?
为什么Java虚拟机JVM要把byte和short的运算都转为int ?
-
Class类的文件结构
方法表,属性表…
编译与优化
-
HotSpot虚拟机 JIT
-
解释执行
逐条将字节码翻译成机器码并执行
-
即时编译(Just-in-time ,JIT)
将一个方法中包含的所有字节码编译成机器码后再执行。
-
-
逃逸分析
System#exit
- 注册的关闭勾子会在以下几种时机被调用到
- 程序正常退出
- 最后一个非守护线程执行完毕退出时
- System.exit方法被调用时
- 程序响应外部事件
- 程序响应用户输入事件,例如在控制台按ctrl+c(^+c)
- 程序响应系统事件,如用户注销、系统关机等
-
这种方法永远不会正常返回。
意味着该方法不会返回;一旦一个线程进入那里,就不会再回来了。
链接:
-
最后一楼说了:将A线程变为while(true) 一直执行,就会发现A线程也会中止。两个线程各自执行,之前都循环十次,A线程可能在B线程调用System.exit(0)之前就执行完了
GC性能优化,日志解读
-
GC算法
-
可能导致FullGC的原因有以下几种。
- 老年代空间不足。
- 永生代或者元数据空间不足。
- 程序执行了System.gc() //建议jvm执行fullgc,并不一定会执行。
- CMS GC时出现promotion failed和concurrent mode failure
- YoungGC时晋升老年代的内存平均值大于老年代剩余空间(执行minor gc的时候进行的一系列检查)
- 有连续的大对象需要分配
- 执行了jmap -histo:live pid命令 //这个会立即触发fullgc
出现Full GC一般是不正常
-
垃圾回收器有哪些?
-
他们什么阶段会stop the world?
看《深入理解Java虚拟机》3.5节 经典垃圾收集器,这里每种收集器的执行图讲解了哪个阶段会STW
-
JVM默认启用的收集器是哪些?
看《深入理解Java虚拟机》3.7.4节 垃圾收集器参数总结,这个讲解了client和server模式下的默认值,以及开启其他收集器的参数
-
-
CMS之promotion failed & concurrent mode failure
疑问?
然后CMS的并发周期就会被一次Full GC代替,退回到Serial Old收集器进行回收,这是一次长Stop The World
-
-
CMS收集器和G1收集器 他们的优缺点对比
-
-
GC日志
- Full GC日志解读
性能调优工具
-
jps、jmap、jstack、jstat
jstat -gcutil
-
VisualVM
-
Arthas使用指南
Arthas 是基于 Greys 进行二次开发的全新在线诊断工具
QA(疑问)
-
计算机内存模型 与 Java内存模型
-
GC
- static 会被GC回收吗?static的在内存中的存放位置?
- 永久代不够会触发Full GC吗
-
锁
-
synchronized或其他锁的产生的阻塞,其和wait的区别?
-
当一个线程的时间片耗尽之后,其synchronized的代码会发生原子性问题吗?
线程1在执行
monitorenter指令的时候,会对Monitor进行加锁,加锁后其他线程无法获得锁,除非线程1主动解锁。即使在执行过程中,由于某种原因,比如CPU时间片用完,线程1放弃了CPU,但是,他并没有进行解锁。而由于synchronized的锁是可重入的,下一个时间片还是只能被他自己获取到,还是会继续执行代码。直到所有代码执行完。这就保证了原子性。 -
JDK1.6后对锁进行的优化,轻量级锁,偏向锁,锁消除,适应性自旋锁,锁粗化 (自旋锁在1.4就有,只不过默认的是关闭的,jdk1.6是默认开启的)
-
-
反射缺点?
1.由于是本地方法调用,让JVM无法优化(还有JIT?)
2.反射方法调用还有验证过程和参数问题,参数需要装箱拆箱、需要组装成Object[]形式、异常的包装等等问题
Java新特性
Java 7
-
-
java.lang.invoke包
主要包含了
CallSite、MethodHandle、MethodType等类反射获取的信息比MethodHandle要多。 反射是模拟java代码层面的调用,MethodHandle是模拟字节码层面的调用。
MethodHandle和反射相比好处是:- 调用 invoke() 已经被JVM优化,类似直接调用一样。
- 性能好得多,类似标准的方法调用。
- 当我们创建MethodHandle 对象时,实现方法检测,而不是调用invoke() 时。
-
新增了invokedynamic指令
-
-
ForkJoin
Java 8
-
时间类:
Instant和LocalDate,LocalTime,LocalDateTime如果是JDK8的应用,可以使用Instant代替Date,LocalDateTime代替Calendar,DateTimeFormatter代替Simpledateformatter,官方给出的解释:simple beautiful strong immutable thread-safe。
附:测试代码请看
metis: com.ariescat.metis.base.time.LocalDateTimeTest -
stream
- parallelStream
-
函数式编程
-
Optional类
-
Supplier接口和Consumer接口 (JDK8以下可用guava替代)
Alyx的FileLoader优化用到了Supplier
-
CompletableFuture 强大的函数式异步编程辅助类
可以比较一下 Google Guava,其也提供了通用的扩展 Future:ListenableFuture、SettableFuture 以及辅助类 Futures 等,方便异步编程。
- windforce AbstractChatChannel
- Java CompletableFuture 详解 · 鸟窝 (colobu.com)
- [译]20个使用 Java CompletableFuture的例子 · 鸟窝 (colobu.com)
-
语法糖
-
Lambda
-
实现原理
-
非捕获式(non-capturing lambda)和捕获式(capturing lambda)
-
Java中的lambda每次执行都会创建一个新对象吗?
测试代码:
study-metis: com.ariescat.metis.base.jdk8.lambda.LambdaTest2,参考链接
-
-
::(双冒号)的实现原理
List<String> al = Arrays.asList("a", "b", "c", "d"); al.forEach(AcceptMethod::printValur); //下面的方法和上面等价的 Consumer<String> methodParam = AcceptMethod::printValur; //方法参数 al.forEach(x -> methodParam.accept(x));//方法执行accept
-
-
JVM
- 元空间(Metaspace)
Java 9
- Reactive Streams
- Flow API
Java 11
- 直接运行源代码
QA(疑问)
Web
分布式 session 一致性
- session复制,对web服务器(例如Tomcat)进行搭建集群
- session绑定,使用nginx
ip-hash策略,无论客户端发送多少次请求都被同一个服务器处理 - 基于redis存储,spring为我们封装好了spring-session,直接引入依赖即可
必会框架
工具库
Apache commons
- Commons IO
FileAlterationMonitor和FileAlterationObserver(Alyx曾发现这里每隔10秒会涨10M内存,待研究)
- Commons Lang3等
Google Guava
Google Guava 是 Google 公司内部 Java 开发工具库的开源版本。Google 内部的很多 Java 项目都在使用它。它提供了一些 JDK 没有提供的功能,以及对 JDK 已有功能的增强功能。
- 主要包括了:
- 集合(Collections)
- 缓存(Caching)
- 原生类型支持(Primitives Support)
- 并发库(Concurrency Libraries)
- 通用注解(Common Annotation)
- 字符串处理(Strings Processing)
- 数学计算(Math)
- I/O事件
- 总线(EventBus)
- 一些有用的小工具:
BloomFilter布隆过滤器的实现
- 源码分析:https://ifeve.com/google-guava
Json
懒人工具
缓存
-
Guava的缓存
Guava Cache说简单点就是一个支持LRU的ConcurrentHashMap
-
Caffeine 来自未来的缓存
Caffeine是基于JAVA 1.8 Version的高性能缓存库。Caffeine提供的内存缓存使用参考Google guava的API。Caffeine是基于Google Guava Cache设计经验上改进的成果。
时间库
- joda 对时间的操作
- Quartz 定时任务
日志
- 区分
commons-logging,slf4j,log4j,logback- 了解
jcl-over-slf4j,jul-to-slf4j这些jar的作用 - 了解
log4j和log4j2的区别,lmax disruptor应用场景
- 了解
Flume日志采集系统,一般用于日志聚合
ASM神器
spring-core自带有asm,org.ow2.asm也是一个轻量级的jar
还有byte buddy库,javassist库
Spring
最好能抽空看看源码,最起码bean的生命周期,如何解决循环依赖,父子容器,还有boot的启动流程,事务实现原理,动态代理原理等,你知道越多越好。
-
Spring AOP
-
AOP原理,ProxyFactory
-
AOP中Pointcut,Advice 和 Advisor 三个概念 还有Advised
Advised->在Spring中创建了AOP代理之后,就能够使用org.springframework.aop.framework.Advised接口对它们进行管理。 任何AOP代理都能够被转型为这个接口,不论它实现了哪些其它接口
Advisor->类似使用Aspect的@Aspect注解的类
Advice->@Before、@After、@AfterReturning、@AfterThrowing、@Around
Pointcut->@Pointcut
-
-
Spring tx
<tx:annotation-driven/>的理解 -
Spring Webflux (reactive web框架,与前端Flux架构名字相同)
命令式编程 VS 响应式编程
-
Spring Data
-
与其他构架的整合
SpringBoot
SpringCloud
Web
-
JAX-RS
全称:Java API for RESTful Web Services,是一套用java实现REST服务的规范,提供了一些标注将一个资源类,一个POJOJava类,封装为Web资源。
包括:
- @Path,标注资源类或方法的相对路径
- @GET,@PUT,@POST,@DELETE,标注方法是用的HTTP请求的类型
- @Produces,标注返回的MIME媒体类型
- @Consumes,标注可接受请求的MIME媒体类型
- @PathParam,@QueryParam,@HeaderParam,@CookieParam,@MatrixParam,@FormParam,分别标注方法的参数来自于HTTP请求的不同位置,例如@PathParam来自于URL的路径,@QueryParam来自于URL的查询参数,@HeaderParam来自于HTTP请求的头信息,@CookieParam来自于HTTP请求的Cookie
Eureka的ApplicationResource有用到
ORM库
-
hibernate
查询:HQL查询,QBC查询,SQL查询
级联查询:一对一,一对多(多对一),多对多;懒加载,1+n问题
其他:
-
session.get(): 非懒加载方法
session.load(): 默认就是是懒加载
-
抓取策略(fetch)和 懒加载(lazy)
-
Netty
-
Netty的线程模型
通过Reactor模型基于多路复用器接收并处理用户请求,内部实现了两个线程池,boss线程池和work线程池,其中boss线程池的线程负责处理请求的accept事件,当接收到accept事件的请求时,把对应的socket封装到一个NioSocketChannel中,并交给work线程池,其中work线程池负责请求的read和write事件
-
NioEventLoop设计原理
-
定时任务的原理
-
netty对象池使用与回收
-
时间轮算法
hashWheel定时器和Quartz的区别:
1)Quartz将定时任务分为任务和触发器,而hashWheel只有任务的概念2)Quartz通过一个TreeSet对所有的触发器进行管理,而hashWheel通过一个hash轮来对所有的任务进行管理
3)Quartz能够非常方便的删除定时任务,而netty的hashWheel暂时没有删除任务的接口(除非自己实现一个hashWheel定时器)
4)Quartz有一个专门的调度线程对任务进行管理,任务执行有另外专门的线程池,而hashWheel用一个线程实现对任务的管理和任务的执行。
5)Quartz能够通过序列化,将定时任务保存在数据库,而hashWheel不能
总的来说,Quartz的功能相对强大,而hashWheel相对要轻量级一点。
-
附:
个人认为netty对用户来说是异步,但是实际底层IO是IO多路复用模型,本质上还是一种同步非阻塞(是的,个人认为IO多路复用模型还是同步非阻塞,并且真正的IO操作都将阻塞应用线程),他只是多了一个Selector(需要底层操作系统支持),如此一个线程就可以控制大量的通信(相比传统IO,不管他是不是非阻塞)。
另看 IO#IO概念,这里也收录了一些理解
Disruptor
-
背景
-
并发中的伪共享问题
-
代码的并发执行大约是两件事:互斥和变化的可见性。
互斥是关于管理某些资源的竞争更新。
变化的可见性是关于控制何时使这些更改对其他线程可见。
-
设计上的优势
- 内部数据存储使用环形缓冲(Ring Buffer),这样分配支持了CPU缓存位置预测,GC的压力更小
- 尽量使用无锁设计,合理使用CAS
- 优化数据结构(填充缓存行),解决伪共享问题
- 合理位运算(如2次方幂求模),合理使用Unsafe
-
策略
WaitStrategy可以选择YieldingWaitStrategy(无锁) -
参考博客
- 解读Disruptor系列,这个系列挺好的,他每篇文章后面都有份参考资料,也可以认真看看
-
扩展
- AtomicXXX.lazySet 这个方法的作用(Sequence#set相当于AtomicLong#lazySet)
- Unsafe类的作用?为什么要用这个类?除了JDK,在Netty、Spring、Kafka、Storm等非常多的流行开源项目中都使用了Unsafe
中间件
ActiveMQ
Elasticsearch
原子类型集合库
避免开销很大的装箱/拆箱操作,节省了原始类型装箱消耗的内存
-
Koloboke
-
Eclipse Collections
Akka
- Actor模型
- akka设计模式系列-基础模式
RxJava
” a library for composing asynchronous and event-based programs using observable sequences for the Java VM “ (一个在 Java VM 上使用可观测的序列来组成异步的、基于事件的程序的库)
新型编程思想
Reative(响应式)编程
Reactive响应式(反应式)编程 是一种新的编程风格,其特点是异步或并发、事件驱动、推送PUSH机制以及观察者模式的衍生。
JVM应用:RxJava、Akka、Actors模型、Vert.x、Webflux
领域驱动设计
他是综合软件系统分析和设计的面向对象建模方法,如今已经发展为一种针对大型复杂系统的领域建模与分析方法。
将要解决的业务概念和业务规则转换为软件系统中的类型及类型的属性与行为,通过合理运用面向对象的封装、继承、多态等设计要素,降低或隐藏整个系统的业务复杂性,并使得系统具有更好的扩展性,应对纷繁多变的现实业务问题。
——抄录于《高可用可伸缩微服务架构:基于Dubbo、Spring Cloud和Service Mesh》2.1节
分布式基石
-
理论基石CAP原理
C - Consistent ,一致性
A - Availability ,可用性
P - Partition tolerance ,分区容忍性
一句话概括 CAP 原理就是——网络分区发生时,一致性和可用性两难全
-
一致性Hash
-
RPC
RPC涉及:通讯,序列化,超时,重发(重复),消息顺序,负载 等等。(个人理解)
- 协议:thrift 等等
- JavaRMI
- HSF 阿里巴巴集团内部使用的分布式服务框架 High Speed Framework
-
分布式锁
分布式锁一般有三种实现方式:1. 数据库乐观锁;2. 基于Redis的分布式锁;3. 基于ZooKeeper的分布式锁
-
分布式事务
- 分布式事务与一致性算法Paxos & raft & zab
- atomikos:4.0 atomikos JTA/XA全局事务
- xaresource
- 分布式事务
- 分布式事务系列(2.1)分布式事务的概念
Zookeeper
高可用技术
-
服务器端如何处理超大量合法请求?
服务器架构层面,做负载均衡,将请求分发给其它服务器处理。
软件服务架构层面,做请求队列,将1w个请求放入队列,业务处理完的请求再返回。
代码层面,优化业务处理,把单机请求做到支持1w并发。
前沿技术
Docker
微服务化
ServiceMesh(服务网格)
中台
大数据
人工智能、区块链等
编程工具
- 构建工具
- Maven
- Gradle
- 十分钟理解Gradle - Bonker - 博客园
- 慕课实战:Gradle3.0自动化项目构建技术精讲+实战
- 版本管理工具
- Git
- Jenkins
C/C++
在学习skynet源码的时候,需要看C和lua,因此这里记一下C相关的用法
-
-
利用一个二级指针来实现
//5行2列的数组 int **p = (int **)malloc(sizeof(int *) * 5); for (int i = 0; i < 5; ++i) { p[i] = (int *)malloc(sizeof(int) * 2); } //输出数组每个元素地址 printf("%p\n", &p[i][j]); -
利用数组指针来实现
//申请一个5行2列的整型数组 int(*p)[2] = (int(*)[2])malloc(sizeof(int) * 5 * 2); //输出数组每个元素地址 printf("%p\n", &p[i][j]); -
利用一维数组来模拟二维数组
int *p = (int *)malloc(sizeof(int) * 5 * 2); //输出数组每个元素地址 printf("%p\n", &p[i*2+j]);malloc返回的其实是void *,所以其需要强转,void *的用处还有memcpy,memset等
-
-
内存对齐 是什么?
脚本语言
-
动态语言与动态类型语言
动态语言:(Dynamic programming Language -动态语言或动态编程语言),动态语言是指程序在运行时可以改变其结构,新的函数可以被引进,已有的函数可以被删除等在结构上的变化。
动态类型语言:动态类型语言是指在运行期间才去做数据类型检查的语言,说的是数据类型,动态语言说的是运行是改变结构,说的是代码结构。
Groovy
- 30分钟groovy快速入门并掌握
- Groovy 语言快速入门
- Groovy 与 Java
- Groovy as DSL 与 Gradle
数据结构
-
链表,栈,队列
-
数组,矩阵
-
图
-
堆:一个可以被看做一棵树的数组
-
二叉树
-
遍历
递归遍历,非递归遍历
-
完全二叉树
-
满二叉树
-
平衡二叉树
- AVL树
- 红黑树
- Treap
- BST
-
B树、B-树、B+树、B*树 区别?
- B-tree树即B树,是一种多路搜索树
- B树的两个明显特点
- 树内的每个节点都存储数据
- 叶子节点之间无指针相邻
- B+树的两个明显特点
- 数据只出现在叶子节点
- 所有叶子节点增加了一个链指针
- B*树是B+树的变体,在B+树的非根和非叶子结点再增加指向兄弟的指针
- B+树相比B树的优势
- 单一节点存储更多的元素,使得查询的IO次数更少;
- 所有查询都要查找到叶子节点,查询性能稳定;
- 所有叶子节点形成有序链表,便于范围查询。
- 要了解一下他们的查找,插入,删除
-
-
跳跃表
-
布隆过滤器,位图,hyperloglog
-
倒排索引
算法
-
常见算法
-
排序
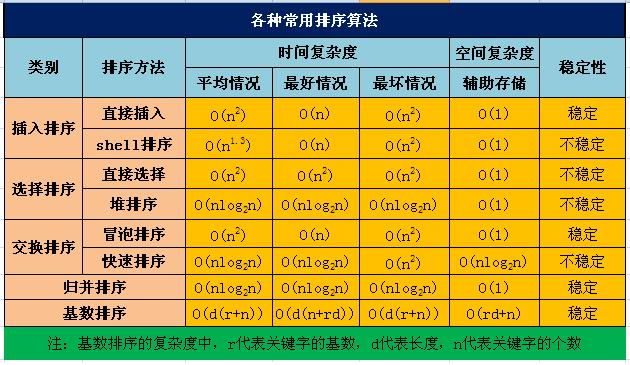
- 八大排序算法比较:
-
希尔排序
时间复杂度?
-
堆排序
如何建堆 和调整堆?
-
快排
快排最好最坏的情况?优化方案?
-
归并排序
-
其他
-
Java中
Colletions.sort和Arrays.sort分别用了什么排序算法呢 -
这里给出了双路快排,三路快排,自底向上的归并排序算法等解析
附:关于他双路快排的实现:
while ((i < right) && (arr[i] < v)) i++; // 使用索引i从左往右遍历直到 arr[i] < v while ((j > left + 1) && (arr[j] > v)) j--; // 使用索引j从右往左遍历直到 arr[j] > v个人认为还可以优化,把相等的情况考虑进去,如下:
while ((i < right) && (arr[i] <= v)) i++; // 使用索引i从左往右遍历直到 arr[i] < v while ((j > left + 1) && (arr[j] >= v)) j--; // 使用索引j从右往左遍历直到 arr[j] > v
-
-
查找算法
二分查找,索引,倒排索引
-
KPM 算法
-
补充:这篇博客的数组并不是next数组,而是”部分匹配值”数组,就是”前缀”和”后缀”的最长的共有元素的长度
-
该博客分析了
k = next[k]的问题 -
KMP算法及优化 - 疯狂的爱因斯坦 - SegmentFault
该博客讲解了KPM的优化问题
-
-
递归
斐波那契数列,其时间复杂度和空间复杂度
-
树
- 最小生成树算法:Kruskal算法,Prim算法
-
最短路径算法:Dijkstra算法,Bellman-Ford算法,Floyd算法和SPFA算法
-
-
五大常用算法:贪婪算法,动态规划算法,分治算法,回溯算法以及分支限界算法
-
-
最长递增子序列
解法1:最长公共子序列法
解法2:动态规划法(时间复杂度O(N^2))
dp[i]表示以标识为i的元素为递增序列结尾元素的最长递增子序列的长度
解法3:O(NlgN)算法
b[i]只是存储的对应长度为i的LIS的最小末尾
-
最长公共子序列
用dp[i][j]来表示A串中的前i个字符与B串中的前j个字符的最长公共子序列长度
-
最长公共子串
这个问题与上面的问题类似,区别点在于这里是子串,是连续的,令dp[i][j]表示A串中的以第i - 1个字符与B串中的以第j - 1个字符结尾的最长公共子串的长度
-
最小编辑代价问题
首先令dp[i][j]表示将A串中的前i个字符转换成B串中的前j个字符所需要的代价
-
-
-
启发式算法
- 遗传算法(GA)
-
算法复杂度
-
多项式时间
一种是O(1),O(log(n)),O(n^a)等,我们把它叫做多项式级的复杂度,因为它的规模n出现在底数的位置;另一种是O(a^n)和O(n!)型复杂度,它是非多项式级的。后者的复杂度无论如何都远远大于前者,其复杂度计算机往往不能承受。原文
这里引出几个问题:
- NP问题:就是可以(多知项式时间内)短时间内验证一个答案正确性的问题。
- NP完全问题:第一个条件,可以这么说,就是道你如果能解决A问题,则通过A问题可以解决B问题,那么回A问题比B问题复杂,当所有的问题都可以通过A问题的解决而解决的话,那么A问题就可以称为NP完全问题,第二个条件,就是答A问题属于NP问题。
-
-
算法思想
- 双指针,贪心,动态规划
- 递推
-
练习平台
字符编解码
-
字符集
-
ASCII
-
Unicode
目前Unicode字符分为17组编排,0x0000至0x10FFFF,每组称为平面(Plane),每个面拥有65536个码位,共1114112个。
-
-
字符编码
UTF-32、UTF-16和 UTF-8 是 Unicode 标准的编码字符集的字符编码方案
-
附:
-
Java的
char内部编码为UTF-16,而与Charset.defaultCharset()无关。看 Unicode 编码理解 可知
UTF-16编码完全可以满足Unicode 的17组编排(平面),因为有平面0的0xD800-0xDFFF代理区。关于java中char占几个字节,汉字占几个字节,这里指出Java中的
char是占用两个字节,只不过有些字符需要两个char来表示,同时这篇博客也给了一个官方Oracle链接里面明确的说明了值在16位范围之外且在0x10000到0x10FFFF范围内的字符称为补充字符,并定义为一对char值。测试代码:
public static void main(String[] args) { char[] c = new char[]{'一'}; System.err.println(Integer.toHexString(c[0])); String s = new String(c); // String#length事实上调用了char[].length System.err.println(s + " " + s.length()); String str = "一"; System.err.println(str + " " + str.length()); // Unicode编码 汉字扩展B '𠀀' 字 c = new char[]{'\uD840', '\uDC00'}; s = new String(c); System.err.println(s + " " + s.length()); str = "\uD840\uDC00"; System.err.println(str + " " + str.length()); // 输出:由输出可见这个字用了两个char来存 // 一 1 // 一 1 // 𠀀 2 // 𠀀 2 }
-
-
参考博客:
-
吴秦(Tyler)字符集和字符编码(Charset & Encoding)
-
廖雪峰 字符串和编码
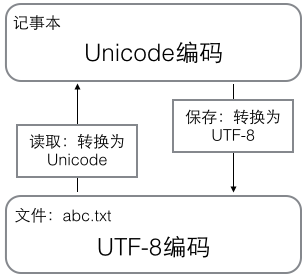
该文有简单有效的解释了:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。 用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
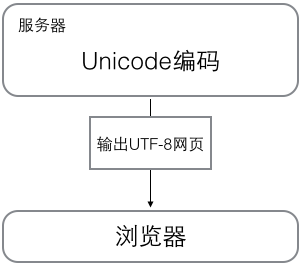
所以你看到很多网页的源码上会有类似
<meta charset="UTF-8" />的信息,表示该网页正是用的UTF-8编码。
-
-
-
Base64编码:
Base64编码本质上是一种将二进制数据转成文本数据的方案。对于非二进制数据,是先将其转换成二进制形式,然后每连续6比特(2的6次方=64)计算其十进制值,根据该值在上面的索引表中找到对应的字符,最终得到一个文本字符串。
-
常见问题处理之Emoji
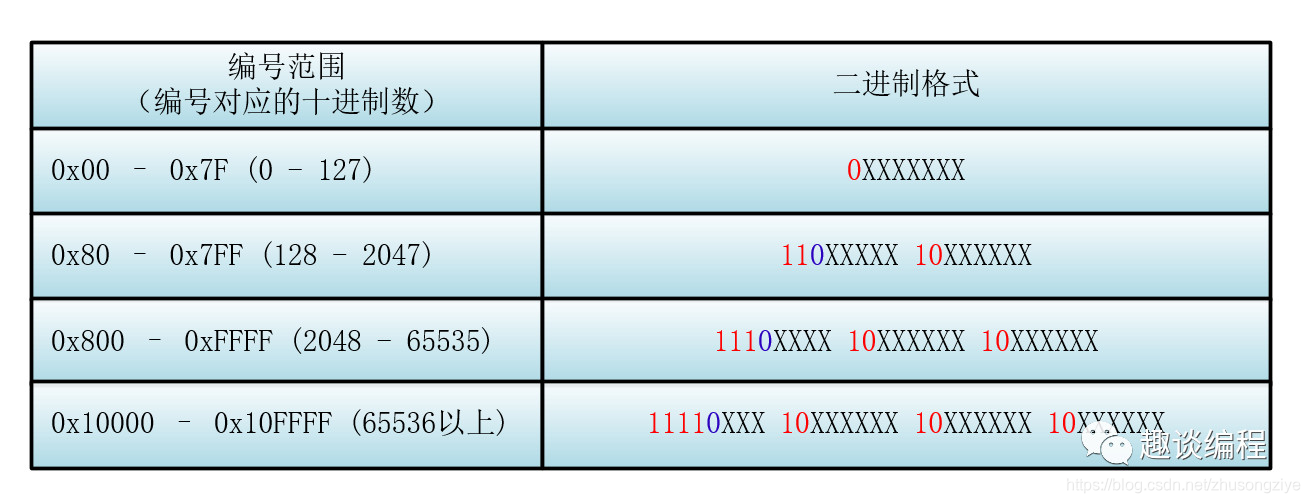
所谓Emoji就是一种在Unicode位于\u1F601–\u1F64F区段的字符。这个显然超过了目前常用的UTF-8字符集的编码范围\u0000–\uFFFF。Emoji表情随着IOS的普及和微信的支持越来越常见。
那么Emoji字符表情会对我们平时的开发运维带来什么影响呢?最常见的问题就在于将他存入MySQL数据库的时候。一般来说MySQL数据库的默认字符集都会配置成UTF-8,mysql支持的 utf8 编码最大字符长度为 3 字节,而utf8mb4在5.5以后才被支持,也很少会有DBA主动将系统默认字符集改成utf8mb4。那么问题就来了,当我们把一个需要4字节UTF-8编码才能表示的字符存入数据库的时候就会报错:ERROR 1366: Incorrect string value: ‘\xF0\x9D\x8C\x86’ for column 。 如果认真阅读了上面的解释,那么这个报错也就不难看懂了。我们试图将一串Bytes插入到一列中,而这串Bytes的第一个字节是\xF0意味着这是一个四字节的UTF-8编码。但是当MySQL表和列字符集配置为UTF-8的时候是无法存储这样的字符的,所以报了错。
那么遇到这种情况我们如何解决呢?有两种方式:升级MySQL到5.6或更高版本,并且将表字符集切换至utf8mb4。第二种方法就是在把内容存入到数据库之前做一次过滤,将Emoji字符替换成一段特殊的文字编码,然后再存入数据库中。之后从数据库获取或者前端展示时再将这段特殊文字编码转换成Emoji显示。第二种方法我们假设用--1F601--来替代4字节的Emoji,那么具体实现python代码可以参见Stackoverflow上的回答
-
补码
补码(为什么按位取反再加一):告诉你一个其实很简单的问题 原文
其核心思想就是:一个正数对应的负数(也就是俩相反数),这两个数的二进制编码加起来必须等于0才对
网络
-
协议
-
底层网络协议
ARP,ICMP(网际控制信息协议),路由选择,DHCP,NAT
-
TCP/IP
-
- 三次挥手是确保双方都能收和发的最少确认次数
- 四次挥手中间的两步并不总是会合成一步走,因为服务端处于“半关闭状态”,可能还有剩下的消息没发完,客户端此时能收不能发
- 四次挥手的time_wait状态,2MSL(MSL为报文最大生存时间,一般2分钟,可更改),作用是重传最后一个ack报文
-
拥塞算法:慢开始 、 拥塞避免 、快重传 和 快恢复
两者的区别:流量控制是为了预防拥塞。如:在马路上行车,交警跟红绿灯是流量控制,当发生拥塞时,如何进行疏散,是拥塞控制。流量控制指点对点通信量的控制。而拥塞控制是全局性的,涉及到所有的主机和降低网络性能的因素。
-
TCP和UDP的区别
TCP/IP协议是一个协议簇。里面包括很多协议的。UDP只是其中的一个。之所以命名为TCP/IP协议,因为TCP,IP协议是两个很重要的协议,就用他两命名了。原文
-
-
http/https
- 彻底掌握网络通信 (httpclien,asynchttpclient,HttpURLConnection,OkHttp3)
- 一次经典的错误:https://github.com/Ariescat/lqz-test/blob/master/base-test/src/main/http/http.log
-
websocket
-
-
非对称加密
在非对称加密中使用的主要算法有:RSA、Elgamal、Rabin、D-H(Diffie-Hellman)、ECC(椭圆曲线加密算法)等
-
https
https客户端无法判断自己收到的服务器的公钥是否是正确的,是否在服务器发送给客户端的过程中被第三方篡改了,所以还需要证明公开密钥正确性的数字证书。
https可以解决中间人劫持?
-
ssl/tls
了解他们的握手过程
-
ssh
-
数字签名,数字证书
浏览器一般怎样校验证书呢?
-
了解几个本质:(原文)
- 解决内容可能被窃听的问题——非对称加密
- 解决报文可能遭篡改问题——数字签名
- 解决通信方身份可能被伪装的问题——认证
-
-
网络攻击
- DDoS攻击
-
ping 的实现:
- 首先查本地arp cache信息,看是否有对方的mac地址和IP地址映射条目记录
- 如果没有,则发起一个arp请求广播包,等待对方告知具体的mac地址
- 收到arp响应包之后,获得某个IP对应的具体mac地址,有了物理地址之后才可以开始通信了,同时对ip-mac地址做一个本地cache
- 发出icmp echo request包,收到icmp echo reply包
-
反向代理为何叫反向代理?原文
IO
-
IO操作
-
《Netty Zookeeper Redis 高并发实战》2.2节
-
同步、异步:
- 概念:消息的通知机制
- 解释:涉及到IO通知机制;所谓同步,就是发起调用后,被调用者处理消息,必须等处理完才直接返回结果,没处理完之前是不返回的,调用者主动等待结果;所谓异步,就是发起调用后,被调用者直接返回,但是并没有返回结果,等处理完消息后,通过状态、通知或者回调函数来通知调用者,调用者被动接收结果。
阻塞、非阻塞:
- 概念:程序等待调用结果时的状态
- 解释:涉及到CPU线程调度;所谓阻塞,就是调用结果返回之前,该执行线程会被挂起,不释放CPU执行权,线程不能做其它事情,只能等待,只有等到调用结果返回了,才能接着往下执行;所谓非阻塞,就是在没有获取调用结果时,不是一直等待,线程可以往下执行,如果是同步的,通过轮询的方式检查有没有调用结果返回,如果是异步的,会通知回调。
- Reactor模式
零拷贝
-
传统的文件传输,DMA技术
DMA 是一种允许外围设备(硬件子系统)直接访问系统主内存的机制。也就是说,基于 DMA 访问方式,系统主内存于硬盘或网卡之间的数据传输可以绕开 CPU 的调度。
-
Linux支持的(常见)零拷贝
mmap内存映射,sendfile(linux 2.1支持),Sendfile With DMA Scatter/Gather Copy(可以看作是sendfile的增强版,批量sendfile),splice(linux 2.6.17 支持)。
Linux零拷贝机制对比:无论是传统IO方式,还是引入零拷贝之后,2次DMA copy 是都少不了的。因为两次DMA都是依赖硬件完成的。
-
PageCache,磁盘高速缓存
主要是两个优点:缓存最近被访问的数据,预读功能
但是,在传输大文件(GB 级别的文件)的时候,PageCache 会不起作用,那就白白浪费 DRM 多做的一次数据拷贝,造成性能的降低,即使使用了 PageCache 的零拷贝也会损失性能
-
直接I/O
-
大文件传输
「异步 I/O + 直接 I/O」来替代零拷贝技术
-
Java NIO引入了用于通道的缓冲区的ByteBuffer。 ByteBuffer有三个主要的实现:
HeapByteBuffer,DirectByteBuffer,MappedByteBuffer
-
Netty中的零拷贝
Netty中的Zero-copy与上面我们所提到到OS层面上的Zero-copy不太一样, Netty的Zero-copy完全是在用户态(Java层面)的,它的Zero-copy的更多的是偏向于优化数据操作这样的概念。
- Netty提供了CompositeByteBuf类,它可以将多个ByteBuf合并为一个逻辑上的ByteBuf,避免了各个ByteBuf之间的拷贝。
- 通过wrap操作,我们可以将byte[]数组、ByteBuf、 ByteBuffer 等包装成一个 Netty ByteBuf对象,进而避免了拷贝操作。
- ByteBuf支持slice 操作,因此可以将ByteBuf分解为多个共享同一个存储区域的ByteBuf,避免了内存的拷贝。
- 通过FileRegion包装的FileChannel.tranferTo实现文件传输,可以直接将文件缓冲区的数据发送到目标Channel,避免了传统通过循环write方式导致的内存拷贝问题。
前三个都是 广义零拷贝,都是减少不必要数据copy;偏向于应用层数据优化的操作。
-
参考:
-
IO 操作的真正耗时
我们开始以为 write 操作是要等到对方收到消息才会返回,但实际上不是这样的。write操作只负责将数据写到本地操作系统内核的发送缓冲然后就返回了。剩下的事交给操作系统内核异步将数据送到目标机器。但是如果发送缓冲满了,那么就需要等待缓冲空出空闲空间来,这个就是写操作 IO 操作的真正耗时。
我们开始以为 read 操作是从目标机器拉取数据,但实际上不是这样的。read 操作只负责将数据从本地操作系统内核的接收缓冲中取出来就了事了。但是如果缓冲是空的,那么就需要等待数据到来,这个就是读操作 IO 操作的真正耗时。
这里可以配合《Netty、Redis、Zookeeper高并发实战》2.2节四种主要的IO模型来看一下。
MySQL
数据类型
- MySQL中的int(M),int(M)里的M表示最大显示宽度,当加上zerofill才会表现出效果来。
- unsigned
- 编码
- utf8_general_ci、utf8_unicode_ci和utf8_bin的区别
- 彻底解决mysql中文乱码 - CSDN博客
SQL语句
-
select
select: 即最常用的查询,是不加任何锁的
select … lock in share mode: 会加共享锁(Shared Locks)
select … for update: 会加排它锁
-
联接子句 union,join
锁
-
前言
表锁,页面锁,行锁,共享锁,排它锁,意向锁,记录锁,间隙锁,临键锁……这些都是什么鬼???
-
机制
-
共享锁(读锁,S锁)
又称读锁,若事务T对数据对象A加上S锁,则事务T可以读A但不能修改A,其他事务只能再对A加S锁,而不能加X锁,直到T释放A上的S锁。
这保证了其他事务可以读A,但在T释放A上的S锁之前不能对A做任何修改。
-
排他锁(写锁,X锁) 又称写锁。若事务T对数据对象A加上X锁,事务T可以读A也可以修改A,其他事务不能再对A加任何锁,直到T释放A上的锁。
这保证了其他事务在T释放A上的锁之前不能再读取和修改A。
-
-
粒度
MySQL 不同的存储引擎支持不同的锁机制
表锁:开销小,加锁快;不会出现死锁
行锁:开销大,加锁慢;会出现死锁
页面锁:开销和加锁时间界于表锁和行锁之间;会出现死锁
默认情况下,表锁和行锁都是自动获得的,不需要额外的命令。
-
InnoDB行级锁和表级锁
InnoDB存储引擎既支持行级锁(row-level locking),也支持表级锁,但默认情况下是采用行级锁。
为了允许行锁和表锁共存,实现多粒度锁机制,InnoDB 还有两种内部使用的意向锁(Intention Locks),这两种意向锁都是表锁:
- 意向共享锁(IS):事务打算给数据行加行共享锁,事务在给一个数据行加共享锁前必须先取得该表的 IS 锁。
- 意向排他锁(IX):事务打算给数据行加行排他锁,事务在给一个数据行加排他锁前必须先取得该表的 IX 锁。
-
InnoDB加锁方法
-
意向锁是 InnoDB 自动加的, 不需用户干预。
-
对于 UPDATE、 DELETE 和 INSERT 语句, InnoDB会自动给涉及数据集加排他锁(X);
-
对于普通 SELECT 语句,InnoDB 不会加任何锁; 事务可以通过以下语句显式给记录集加共享锁或排他锁:
- 共享锁(S):SELECT * FROM table_name WHERE … LOCK IN SHARE MODE。 其他 session 仍然可以查询记录,并也可以对该记录加 share mode 的共享锁。但是如果当前事务需要对该记录进行更新操作,则很有可能造成死锁。
- 排他锁(X):SELECT * FROM table_name WHERE … FOR UPDATE。其他 session 可以查询该记录,但是不能对该记录加共享锁或排他锁,而是等待获得锁
锁只有在执行commit或者rollback的时候才会释放,并且所有的锁都是在同一时刻被释放。
-
-
InnoDB 行锁实现方式
InnoDB 行锁是通过给索引上的索引项加锁来实现的,这一点 MySQL 与 Oracle 不同,后者是通过在数据块中对相应数据行加锁来实现的。InnoDB 这种行锁实现特点意味着:只有通过索引条件检索数据,InnoDB 才使用行级锁,否则,InnoDB 将使用表锁!
-
InnoDB的间隙锁
当我们用范围条件而不是相等条件检索数据,并请求共享或排他锁时,InnoDB会给符合条件的已有数据记录的索引项加锁;对于键值在条件范围内但并不存在的记录,叫做“间隙(GAP)”,InnoDB也会对这个“间隙”加锁,这种锁机制就是所谓的间隙锁(Next-Key锁)。
MySQL默认事务隔离级别是可重复读,这个隔离级别为了避免幻读现象,引入了这个间隙锁,对索引项之间的间隙上锁。
SELECT * FROM t_url_mapping WHERE id>3 LOCK IN SHARE MODE;(SELECT 语句默认不上锁,需显示加锁,该语句加的就是间隙锁)
个人理解:
记录锁(Record Locks):封锁记录,记录锁也叫行锁;例如:
SELECT * FROM
testWHEREid=1 FOR UPDATE;间隙锁(Gap Lock):锁在索引之间或者第一个索引前面或者最后一个索引后面。是一种概念,InnoDB的算法实现是Next-key lock,也属于间隙锁,但他相当于记录锁+间隙锁。
临键锁(Next-key lock):使用索引进行范围查询,左开右闭区间,目的是为了解决幻读的问题。
-
注意死锁
产生:两个或多个事务在同一资源上相互占用,并请求锁定对方占用的资源,从而导致恶性循环。如:
当前事务获得S锁,但是如果当前事务需要对该记录进行更新操作,则很有可能造成死锁。
更新操作必须等待先执行的事务commit后才能执行,如果同时并发太大的时候很容易造成死锁。(搜索
mysql in share mode 死锁)检测死锁:数据库系统实现了各种死锁检测和死锁超时的机制。InnoDB存储引擎能检测到死锁的循环依赖并立即返回一个错误。
死锁恢复:死锁发生以后,只有部分或完全回滚其中一个事务,才能打破死锁,InnoDB目前处理死锁的方法是,将持有最少行级排他锁的事务进行回滚。所以事务型应用程序在设计时必须考虑如何处理死锁,多数情况下只需要重新执行因死锁回滚的事务即可。
-
参考链接:MySQL锁总结
事务
-
事务特性,ACID的含义
-
原子性
a. 事务是一个原子操作单元
b. 要么都做,要么都不做,没有第三种情况
c. 原子性仅能够保证单个事务的一致性!
-
一致性
a. 事务操作前和操作后都必须满足业务规则约束
b. 比如资源数量一致:A向B转账,转账前和转账后AB两个账户的总金额必须是一致的
c. 一致性是最基本的属性,其它的三个属性都为了保证一致性而存在的。为了保证并发情况下的一致性,引入了隔离性,即保证每一个事务能够看到的数据总是一致的,就好象其它并发事务并不存在一样。
-
隔离性
a. 多个并发事务同时对数据进行读写的能力
b. 隔离性可以防止事务并发执行时由于交叉执行导致数据不一致的问题
-
持久性
a. 对数据的修改是永久的
b. 即使出现系统故障也不会丢失
-
-
并发问题:
-
脏读
一个事务正在对一条记录做修改,在这个事务提交之前,别的事务读取到了这个事务修改之后的数据,也就是说,一个事务读取到了其他事务还没有提交的数据,就叫做脏读。
-
不可重复读(第一类不可重复读)
一个事务读某条数据读两遍,读到的是不一样的数据,也就是说,一个事务在进行中读取到了其他事务对旧数据的修改结果。(比如说 我开一个事务 修改某条数据 先查后改 执行修改动作的时候发现这条数据已经被别的事务删掉了)
-
幻读(第二类不可重复读)
一个事务中,读取到了其他事务新增的数据,仿佛出现了幻象。(幻读与不可重复读类似,不可重复读是读到了其他事务update/delete的结果,幻读是读到了其他事务insert的结果)
隔离级别:
-
读未提交(read-uncommitted)
在一个事务中,可以读取到其他事务未提交的数据变化,这种读取其他会话还没提交的事务,叫做脏读现象,在生产环境中切勿使用。
-
读已提交(read-committed)
Sql Server,Oracle默认
在一个事务中,可以读取到其他事务已经提交的数据变化,这种读取也就叫做不可重复读,因为两次同样的查询可能会得到不一样的结果。
-
可重复读(repetable-read)
MySQL默认
在一个事务中,直到事务结束前,都可以反复读取到事务刚开始时看到的数据,并一直不会发生变化,避免了脏读、不可重复读现象,但是在SQL标准中它还是无法解决幻读问题。
-
可串行化(serializable)
这是最高的隔离级别,它强制事务串行执行,避免了前面说的幻读现象,简单来说,它会在读取的每一行数据上都加锁,所以可能会导致大量的超时和锁争用问题。
几个概念:
-
锁:Shared Locks(共享锁/S锁)、Exclusive Locks(排它锁/X锁)、Record Locks(行锁)、Gap Locks(间隙锁)、Next-Key Locks(间隙锁)
Record Locks是加在索引行(对!是索引行!不是数据行!),Gap Locks和Next-Key Locks都属于索引锁
-
快照读(普通读):snapshot read,通过MVCC机制读取历史数据的方式
select * from table ….
-
当前读:current read ,读取数据库最新版本数据的方式
insert、update、delete、select for update、select lock in share mode
-
意向锁:表级别锁
隔离性底层实现原理:
-
MVCC(多版本并发控制)和锁
-
读已提交和可重复读区别主要在于MVCC版本的生成时机
RC是是每次
select时,RR是第一次select时生成版本 -
可串行化级别下,会自动将所有普通
select转化为select ... lock in share mode执行,即针对同一数据的所有读写都变成互斥的了,可靠性大大提高,并发性大大降低。
注意:
-
间隙锁锁住的是索引的间隙,可以理解为范围,如(2,5],(5,7]
-
我们通过
update、delete等语句加上的锁都是行级别的锁。只有LOCK TABLE … READ和LOCK TABLE … WRITE才能申请表级别的锁。 -
RR级别下隐藏着一个操作,就是在事务A提交前,事务B已经进行过一次查询,否则,事务B会读取最新的数据。原文
-
为什么很多文章都产生误传,说是可重复读可以解决幻读问题!原因出自官网的一句话(地址是:
https://dev.mysql.com/doc/refman/5.7/en/innodb-locking.html#innodb-record-locks),原文内容如下By default, InnoDB operates in REPEATABLE READ transaction isolation level. In this case, InnoDB uses next-key locks for searches and index scans, which prevents phantom rows (see Section 14.7.4, “Phantom Rows”).
按照原本这句话的意思,应该是
InnoDB默认用了REPEATABLE READ。在这种情况下,使用next-key locks解决幻读问题!
结果估计,某个国内翻译人员翻着翻着变成了
InnoDB默认用了REPEATABLE READ。在这种情况下,可以解决幻读问题!
然后大家继续你抄我,我抄你,结果你懂的!
显然,漏了”使用了next-key locks!”这个条件后,意思完全改变,我们在该隔离级别下执行语句
select * from tx_tb where pId >= 1;是快照读,是不加任何锁的,根本不能解决幻读问题,除非你用
select * from tx_tb where pId >= 1 lock in share mode;这样,你就用上了next-key locks,解决了幻读问题!
-
其实幻读很多时候是我们完全可以接受的
总结:
隔离级别 读数据一致性 脏读 不可重复读 幻读 读未提交 最低级别,只保证不读取物理上损坏的数据 有 有 有 读已提交 语句级 无 有 有 可重复读 事务级 无 无 可能有 可串行化 最高级别,事务级 无 无 无 参考链接:
-
-
事务传播(其实这个是
Spring的概念,Spring它对JDBC的隔离级别作出了补充和扩展,其提供了7种事务传播行为)- PROPAGATION_REQUIRED:默认事务类型,如果没有,就新建一个事务;如果有,就加入当前事务。适合绝大多数情况。
- PROPAGATION_REQUIRES_NEW:如果没有,就新建一个事务;如果有,就将当前事务挂起。
- PROPAGATION_NESTED:如果没有,就新建一个事务;如果有,就在当前事务中嵌套其他事务。
- PROPAGATION_SUPPORTS:如果没有,就以非事务方式执行;如果有,就使用当前事务。
- PROPAGATION_NOT_SUPPORTED:如果没有,就以非事务方式执行;如果有,就将当前事务挂起。即无论如何不支持事务。
- PROPAGATION_NEVER:如果没有,就以非事务方式执行;如果有,就抛出异常。
- PROPAGATION_MANDATORY:如果没有,就抛出异常;如果有,就使用当前事务。
索引
-
使用场景
索引是在存储引擎层实现的,而不是在服务器层实现的,所以不同存储引擎具有不同的索引类型和实现。
- 对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效。
- 对于中到大型的表,索引就非常有效。
- 但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,可以通过 explain 检查 SQL 的执行计划,比如上面第一种情况,它就不会使用索引
-
B-Tree
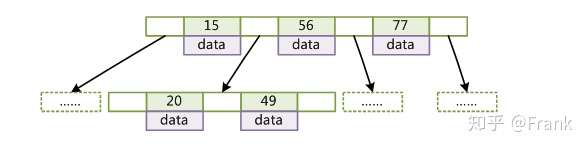
查找算法:首先在根节点进行二分查找,如果找到则返回对应节点的 data,否则在相应区间的指针指向的节点递归进行查找。
-
B+Tree
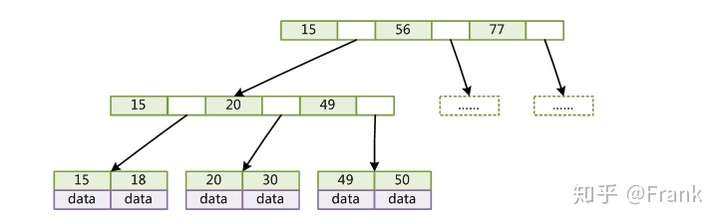
相比B-Tree:
- 内节点不存储 data,只存储 key;
- 叶子节点不存储指针。
一般在数据库系统或文件系统中使用的 B+Tree 结构都在经典 B+Tree 基础上进行了优化,在叶子节点增加了顺序访问指针,做这个优化的目的是为了提高区间访问的性能。
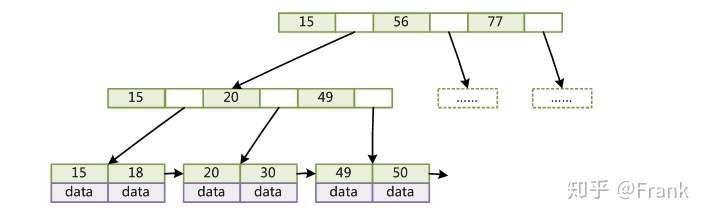
利用计算机预读特性
操作系统一般将内存和磁盘分割成固态大小的块,每一块称为一页,内存与磁盘以页为单位交换数据。数据库系统将索引的一个节点的大小设置为页的大小,使得一次 I/O 就能完全载入一个节点,并且可以利用预读特性,相邻的节点也能够被预先载入。
-
B+Tree 索引
InnoDB 的 B+Tree 索引分为主索引和辅助索引。
主索引的叶子节点 data 域记录着完整的数据记录,这种索引方式被称为聚簇索引。因为无法把数据行存放在两个不同的地方,所以一个表只能有一个聚簇索引。
辅助索引的叶子节点的 data 域记录着主键的值,因此在使用辅助索引进行查找时,需要先查找到主键值,然后再到主索引中进行查找。
-
MySQL索引类型
唯一索引,主键(聚簇)索引,非聚簇索引,全文索引
其实按照定义,除了聚集索引以外的索引都是非聚集索引,只是人们想细分一下非聚集索引,分成普通索引,唯一索引,全文索引。
全文索引有自己的语法格式,使用 match 和 against 关键字,比如
select * from fulltext_test where match(content,tag) against('xxx xxx'); -
缺点
- 创建索引和维护索引要耗费时间,这种时间随着数据量的增加而增加
- 索引需要占用物理空间,除了数据表占用数据空间之外,每一个索引还要占一定的物理空间,如果建立聚簇索引,那么需要的空间就会更大
- 当对表中的数据进行增加、删除和修改的时候,索引也需要维护,降低数据维护的速度
-
索引失效
- 如果条件中有or,即使其中有条件带索引也不会使用 (这就是问什么尽量少使用or的原因)
- 对于多列索引,不是使用的第一部分,则不会使用索引
- like查询是以%开头
- 如果列类型是字符串,那一定要在条件中使用引号引起来,否则不会使用索引
- 如果MySQL估计使用全表扫秒比使用索引快,则不适用索引。
-
在什么情况下适合建立索引
order by、group by、distinct
union
where、join
-
联合索引
最左前缀匹配原则
mysql会一直向右匹配直到遇到范围查询(>、<、between、like)就停止匹配,比如a = 1 and b = 2 and c > 3 and d = 4 如果建立(a,b,c,d)顺序的索引,d是用不到索引的,如果建立(a,b,d,c)的索引则都可以用到,a,b,d的顺序可以任意调整。
-
MYSQL如何挑选索引?
-
参考链接
存储引擎
- MyISAM,InnoDB
日志
-
日志类型
- 逻辑日志:存储了逻辑SQL修改语句
- 物理日志:存储了数据被修改的值
-
binlog
MySQL 的逻辑日志,也叫二进制日志、归档日志,用于记录用户对数据库操作的SQL语句(除了查询语句)信息,以二进制的形式保存在磁盘中。
日志格式:STATMENT、ROW 和 MIXED
STATMENT:基于SQL语句的复制,每一条会修改数据的sql语句会记录到binlog中,是binlog的默认格式。
ROW:基于行的复制,不记录每一条SQL语句的上下文信息,仅保存哪条记录被修改。
MIXED模式是基于 STATMENT 和 ROW 两种模式的混合复制,一般的复制使用STATEMENT模式保存 binlog,对于 STATEMENT 模式无法复制的操作使用ROW模式保存 binlog,MySQL 会根据执行的 SQL 语句选择日志保存方式。
-
redo/undo log
redo log 是 MySQL 的物理日志,也叫重做日志,记录存储引擎 InnoDB 的事务日志。
MySQL 每执行一条 SQL 更新语句,不是每次数据更改都立刻写到磁盘,而是先将记录写到 redo log 里面,并更新内存(这时内存与磁盘的数据不一致,将这种有差异的数据称为脏页),一段时间后,再一次性将多个操作记录写到到磁盘上,这样可以减少磁盘 io 成本,提高操作速度。先写日志,再写磁盘,这就是 MySQL 里经常说到的 WAL 技术,即 Write-Ahead Logging,又叫预写日志。MySQL 通过 WAL 技术保证事务的持久性。
Crash Safe(宕机重启):
有了 redo log,当数据库发生宕机重启后,可通过 redo log 将未落盘的数据(check point之后的数据)恢复,保证已经提交的事务记录不会丢失,这种能力称为crash-safe。 两阶段提交:
有了 redo log,为什么还需要 binlog 呢?先来看看 binlog 和redo log 的区别:
redo log binlog 文件大小 redo log 的大小是固定的。 binlog 可通过配置参数max_binlog_size 设置每个 binlog 文件的大小。 实现方式 redo log 是 InnoDB 引擎层实现的,并不是所有引擎都有。 binlog是 Server 层实现的,所有引擎都可以使用 binlog 日志。 记录方式 redo log 采用循环写的方式记录,当写到结尾时,会回到开头循环写日志。日志上的记录修改落盘后,日志会被覆盖掉,无法用于数据回滚/数据恢复等操作。 binlog 通过追加的方式记录,当文件大小大于给定值后,日志会发生滚动,之后的日志记录到新的文件上,不会覆盖以前的记录。 由 binlog 和 redo log 的区别可知:binlog 日志只用于归档,只依靠 binlog 是没有 crash-safe 能力的。但只有 redo log 也不行,因为 redo log 是InnoDB 特有的,且日志上的记录落盘后会被覆盖掉。因此需要 binlog 和 redo log 二者同时记录,才能保证当数据库发生宕机重启时,数据不会丢失。
-
参考链接
备份与恢复
- 冷备份,热备份
- cp,mysqldump,lvm2快照,xtrabackup
- mysql误删数据快速恢复
高级
-
explain
explain显示了mysql如何使用索引来处理select语句以及连接表。可以帮助选择更好的索引和写出更优化的查询语句。
-
如何快速的删除一张大(TB级别)表?
- 区分drop,truncate,delete
- 利用linux中硬链接
-
慢日志
可以设置一个时间,那么所有执行时间超过这个时间的SQL都会被记录下来。这样就可以通过慢日志快速的找到网站中SQL的瓶颈来进行优化。
分布式
- 主从复制,分库分表
Redis / NoSQL
- Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的 Value 的基础数据结构有string、list、hash、set、zset;
- 有 Bitmaps,HyperLogLog 等多种高级数据结构和算法
- Redis还提供了键过期,发布订阅,事务,Lua脚本,哨兵,Cluster等功能。
-
主要应用:
分布式锁、延时队列、位图、HyperLogLog、布隆过滤器、简单限流(zset)、漏斗限流、GeoHash(地理位置)
-
需要了解的一些原理:
-
Redis的线程模型:单线程,IO多路复用
-
客户端与服务器的通信协议
-
持久化:
使用操作系统的多进程 COW(Copy On Write) 机制来实现快照持久化
bgsave 做全量持久化到 RDB 二进制文件中,aof 做增量持久化,存储的是文本协议数据
-
管道,事务
注意redis事务不保证原子性,不支持回滚。他总结来说:就是一次性、顺序性、排他性的执行一个队列中的一系列命令。其他客户端提交的命令请求不会插入到事务执行命令序列中。
思考一下,为什么这样设计?
-
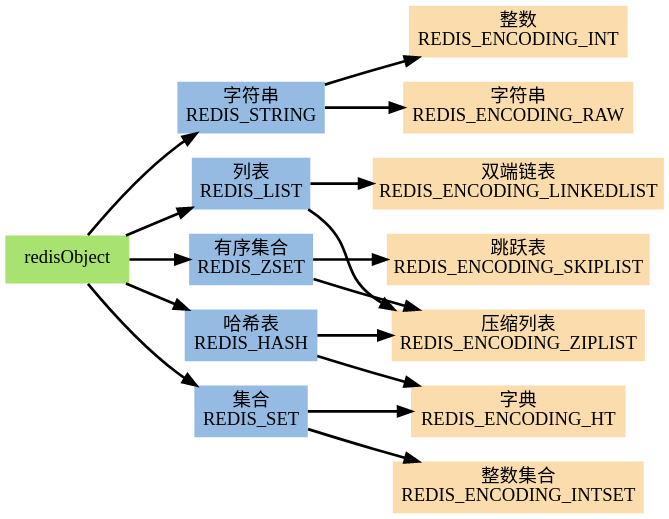
encoding记录了对象所保存的值的编码下图展示了 redisObject 、Redis 所有数据类型、以及 Redis 所有编码方式(底层实现)三者之间的关系:
-
-
拓展
Stream数据结构,Info指令,分布式锁Redlock算法,RedLock,过期清除策略
-
选择hash还是string 存储数据?
-
redis分布式锁
- 单实例中实现分布式锁:setnx(注意删除时最好使用Lua脚本删除,逻辑是先获取key,如果存在并且值是自己设置的就删除此key,否则就跳过)
- 多节点redis实现的分布式锁:RedLock
-
Redis 内存不够时的淘汰策略
LRU 算法和 LFU 算法,redis 对 LRU 的改进
-
缓存穿透解决方案?
布隆过滤器
-
-
Java的Redis客户端:Jedis,Redisson
-
Redisson 不仅封装了 redis ,还封装了对更多数据结构的支持,以及锁等功能,相比于Jedis 更加大。
Redisson的加锁/释放锁都是用Lua脚本,相比于setnx就能实现,为何多此一举?仔细看Lua脚本就会发现考虑得非常全面,其中包括锁的重入性。
-
但Jedis相比于Redisson 更原生一些,更灵活。
-
-
集群
Sentinel,Codis,Cluster
-
源码
- 带有详细注释的 Redis 3.0 代码
- jemalloc,Redis 默认使用 jemalloc(facebook) 库来管理内存
-
一些面试题:
-
防止缓存穿透:增加校验,缓存,布隆过滤器(Bloom Filter),hyperloglog
-
-
书籍
- 《redis设计与实现(第二版)》
- 《Redis 深度历险:核心原理与应用实践》
-
Orther NoSQL
- Memcache
- Redis之与Memcached的比较
- MongoDB
- Elasticsearch
- Memcache
操作系统
- 进程管理
- 内存管理
- 分页管理
-
设备管理
- Windows
- hiberfil.sys和pagefile.sys占用系统空间,其分别是休眠空间和虚拟内存。
- 其他
- 虚拟内存和swap分区
Github干货
-
521xueweihan / HelloGitHub 分享 GitHub 上有趣、入门级的开源项目
-
awesome
-
Java 笔试、面试 知识整理
-
【Java学习+面试指南】 一份涵盖大部分Java程序员所需要掌握的核心知识。
-
Java资源大全中文版,包括开发库、开发工具、网站、博客、微信、微博等,由伯乐在线持续更新。
-
【互联网一线大厂面试+学习指南】进阶知识完全扫盲:涵盖高并发、分布式、高可用、微服务等领域知识,作者风格幽默,看起来津津有味,把学习当做一种乐趣,何乐而不为,后端同学必看
附其CSDN博客(《吊打面试官》系列):https://me.csdn.net/qq_35190492
-
xingshaocheng / architect-awesome
后端架构师技术图谱
-
Java Core Sprout : basic, concurrent, algorithm
-
Java成长路线,但学到不仅仅是Java。
-
-
Java高并发
-
Android
- henrymorgen / android-advanced-decode 《Android进阶解密》源码
-
游戏相关
-
hstcscolor / awesome-gameserver-cn 中文游戏服务器资源大全
-
ARPG
-
永恒之塔开源服务器架构 https://github.com/Aion-server/Aion-unique
-
天堂2 l2jserver2
-
魔兽世界server TrinityCore https://github.com/TrinityCore/TrinityCore
-
-
tinyHeart https://github.com/luckykun/tinyHeart
-
-
常见框架源码
- tomcat
- dubbo
- spring
- zookeeper
-
源码解读
- huangz1990 / redis-3.0-annotated 带有详细注释的 Redis 3.0 代码
知识体系
面经汇总
- Java面经汇总
- 大厂面经
- 经历分享
博客
- 职场
- 年度报告
- 其他
常用社区
必备软件
- everything
- wox(window快速搜索文件启动程序软件)
- 系统镜像
- HTTP接口测试工具
- Postman
- PanDownload
Linux常用服务搭建
(Shadowsocks,Ngrok,Nginx…)
- CentOS7
- MySql
- Jetty
- Shadowsocks
- Nginx
- Ngrok
前端
- HTML/CSS/JS
- ECMAScript
- Bootstrap 教程 - 菜鸟教程
- Vue
- React
- Flux 架构
- 状态管理
- 其他
Android
- Gradle Distributions
- 图表
- hellocharts
- 学习网站
- Material Design
- NavigationView FlaotingActionBar SnackBar
- Design Support Library
- RecyclerView
- SwipeRefreshLayout
- 控件点击水波纹
Unity3d
游戏技术
- AI(状态机 行为树)
- 游戏框架
- skynet
- Pinus
游戏相关
相关书籍
- Java
- 《深入理解Java虚拟机(第3版)(周志明)》
- 《Java并发编程实战》
- 《Effective Java》
- Redis
- 《Redis 深度历险:核心原理与应用实践 (钱文品)》
- 《Redis设计与实现》
- Spring
- 《Spring 源码深度解析 第二版》《Spring实战》
- 《Spring Boot编程思想(核心篇)》
- 《Spring Boot实战》
- 《Spring 微服务实战》
- Netty
- 《Netty权威指南》
- Tomcat
- 《Tomcat架构解析 (刘光瑞)》
- 《漫画算法:小灰的算法之旅》
- 《架构探险分布式服务框架 (李业兵)》
- 《高性能MySQL》
